表格比较是数据分析中的常见任务,尤其是在使用 Power BI 和 Power Query M 时。高效地自动比较数据集并识别差异对于维护数据完整性和准确性至关重要。本文提供了两个自定义 Power Query M 函数,旨在自动执行表格比较,为一般用例和表格结构一致的场景提供解决方案。
通用表格比较函数 (fxCom2Tables)
此函数 fxCom2Tables 旨在实现灵活的表格比较,即使在键列区分大小写的情况下也能正常工作。它执行左外连接,然后比较每个对应的字段值以识别匹配项。
let
fxCom2Tables = (lTable as table, lKeyColNum as number, rTable as table, rKeyColNum as number, optional Comparison as nullable number) as table =>
let
BaseTable = Table.Buffer(lTable),
lKeyColName = Table.ColumnNames(BaseTable){lKeyColNum},
CompareAs = if Comparison = 1 then Comparer.OrdinalIgnoreCase else Comparer.Equals,
AddKeyL = Table.AddColumn(BaseTable, "KeyColCase", each Text.Upper(Text.From(Record.FieldValues(_){lKeyColNum})), type text),
AddKeyR = Table.AddColumn(rTable, "KeyColCase", each Text.Upper(Text.From(Record.FieldValues(_){rKeyColNum})), type text),
Merge = if Comparison = 1 then Table.NestedJoin(AddKeyL, {"KeyColCase"}, AddKeyR, {"KeyColCase"}, "Temp", JoinKind.LeftOuter) else Table.NestedJoin(BaseTable, lKeyColName, rTable, Table.ColumnNames(rTable){rKeyColNum}, "Temp", JoinKind.LeftOuter),
CompareRecord = Table.AddColumn(Merge, "Compare", each
let
ToRemoveCols = {lKeyColName} & {"Temp", "KeyColCase"}
in
if Table.IsEmpty(_[Temp]) then
List.Repeat({0}, Record.FieldCount(Record.RemoveFields(_, ToRemoveCols, MissingField.Ignore)))
else
List.Transform(List.Zip({
Record.FieldValues(Record.ReorderFields(Record.RemoveFields(_, ToRemoveCols, MissingField.Ignore), Table.ColumnNames(Merge), MissingField.Ignore)),
Record.FieldValues(Record.ReorderFields(_[Temp]{0}, ToRemoveCols, MissingField.Ignore), Table.ColumnNames(Merge), MissingField.Ignore))}), each try if _{0} = _{1} then 1 else 0 otherwise 0)
),
tResult = Table.SplitColumn(
Table.TransformColumns(
Table.SelectColumns(CompareRecord, {lKeyColName} & {"Compare"}),
{"Compare", each Text.Combine(List.Transform(_, Text.From), "||"), type text}
),
"Compare",
Splitter.SplitTextByDelimiter("||", QuoteStyle.Csv),
List.Select(List.Difference(Table.ColumnNames(Merge), {"Temp", "KeyColCase"}), each _ <> lKeyColName)
),
Documentation = [
Documentation.Name = "fxCompare2Tables",
Documentation.LongDescription = "返回0表示字段值不匹配,返回1表示字段值匹配。",
Documentation.Category = "Table",
Documentation.Author = "Melissa de Korte",
Documentation.Examples = {
[
Description = " ",
Code = "变量应如何使用。 #(lf) lKeyColNum 和 rKeyColNum 作为键列的从零开始的位置 #(lf) 可选的 Comparison,如果设置为 1,则将忽略键列值的大小写",
Result = " "
]
}
]
in
Value.ReplaceType(fxCom2Tables, Value.ReplaceMetadata(Value.Type(fxCom2Tables), Documentation))此函数接受两个表格(lTable、rTable),每个表格的键列索引(lKeyColNum、rKeyColNum)以及一个可选的 Comparison 参数。将 Comparison 设置为 1 将禁用键列比较的区分大小写。输出表格包含键列和其他列,匹配的字段值显示“1”,输入表格之间不匹配的字段值显示“0”。
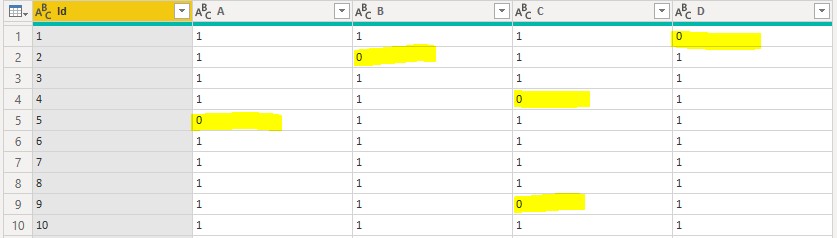 fxCom2Tables Power Query M 函数的输出,显示了两个表格之间的比较结果,匹配项为 1,不匹配项为 0。
fxCom2Tables Power Query M 函数的输出,显示了两个表格之间的比较结果,匹配项为 1,不匹配项为 0。
针对相同结构的优化表格比较函数
如果您的表格始终具有相同的键字段值顺序和列顺序,则使用列表函数的方法效率更高。下面的 fxCompare2Tables 函数利用了这种优化。
let
fxCompare2Tables = (lTable as table, lKeyColNum as number, rTable as table, rKeyColNum as number) as table =>
let
lKeyColName = Table.ColumnNames(lTable){lKeyColNum},
rKeyColName = Table.ColumnNames(rTable){rKeyColNum},
tResult = Table.FromColumns(
{Table.ToColumns(lTable){lKeyColNum}} &
List.Transform(
List.Zip({
Table.ToColumns(Table.RemoveColumns(lTable, lKeyColName, MissingField.Ignore)),
Table.ToColumns(Table.RemoveColumns(rTable, rKeyColName, MissingField.Ignore))
}),
each List.Transform(List.Zip({_{0}, _{1}}), (i) => try if i{0} = i{1} then 1 else 0 otherwise 0)
),
{lKeyColName} & Table.ColumnNames(Table.RemoveColumns(lTable, lKeyColName, MissingField.Ignore))
),
Documentation = [
Documentation.Name = "fxCompare2Tables",
Documentation.LongDescription = "返回0表示字段值不匹配,返回1表示字段值匹配。",
Documentation.Category = "Table",
Documentation.Author = "Melissa de Korte",
Documentation.Examples = {
[
Description = " ",
Code = "变量应如何使用。 #(lf) lKeyColNum 和 rKeyColNum 作为键列的从零开始的位置",
Result = " "
]
}
]
in
Value.ReplaceType(fxCompare2Tables, Value.ReplaceMetadata(Value.Type(fxCompare2Tables), Documentation))这个简化的函数假设表格结构一致,并在移除键列后直接比较相应的列表元素。在保证结构一致性的情况下,它提供了更高的性能。
通过使用这些 fxCompare2Tables 函数,您可以有效地在 Power Query M 中自动比较表格,深入了解数据差异,并确保 Power BI 报告和数据工作流中的数据质量。选择最适合您的表格结构和比较需求的函数以获得最佳结果。