In the realm of data analysis, ensuring data integrity and accuracy is paramount. Whether you are merging datasets, updating information, or simply validating data transformations, the ability to effectively compare datasets is crucial. SAS, a powerful statistical software suite, provides a robust tool for this purpose: Proc Compare. This procedure allows you to meticulously examine the structure and content of two datasets, highlighting both their similarities and differences. Understanding and utilizing PROC COMPARE is an essential skill for any SAS user aiming to maintain data quality and gain deeper insights from comparative analysis.
{width=1280 height=720}Deciphering the Syntax of PROC COMPARE
The fundamental syntax for executing PROC COMPARE is remarkably straightforward, making it accessible even for SAS beginners.
proc compare base = data1 compare = data2; run;In this syntax, data1 represents the base dataset – the dataset considered as the standard or reference point. data2 is the compare dataset, the dataset being evaluated against the base. Executing this simple code will initiate a comprehensive comparison of data1 and data2 across all variables they share.
To illustrate PROC COMPARE in action, let’s utilize two readily available datasets within SAS: sashelp.class and sashelp.classfit. These datasets are part of the SAS Help library and provide a convenient way to explore the procedure’s capabilities.
proc compare base = sashelp.class compare = sashelp.classfit; run;Upon running this code, PROC COMPARE generates a detailed output report, systematically breaking down the comparison into several key sections. Let’s delve into understanding these sections to effectively interpret the results.
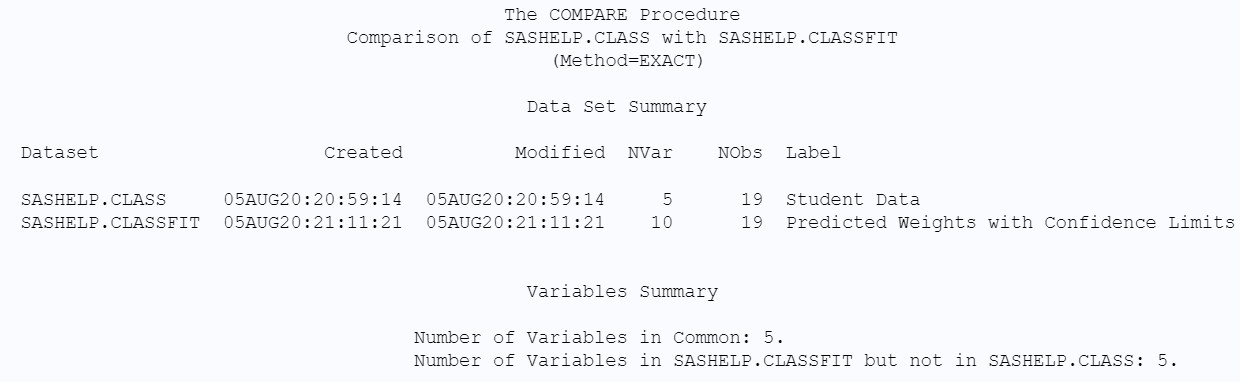
{width=1240 height=382}Unpacking the Dataset Summary
The “Dataset Summary” section provides a high-level overview of the structural attributes of both datasets and highlights any discrepancies. Key elements within this summary include:
- Dataset Creation Dates: Reveals when each dataset was initially created. Differences here might indicate different versions or origins of the data.
- Dataset Modification Dates: Indicates the last time each dataset was altered. Divergent modification dates can signal that one dataset has been updated while the other has not.
- Number of Variables: Shows the count of variables in each dataset. A mismatch suggests variations in the data schema or variable inclusion.
- Number of Observations: Displays the number of rows or observations in each dataset. Different observation counts immediately point to variations in the data volume.
- Labels: Compares dataset labels, if defined. Label discrepancies are less critical for data content but are valuable for metadata consistency.
Variable Summary: Identifying Common and Unique Variables
The “Variable Summary” section categorizes variables based on their presence in the datasets:
- Variables in Common: Lists variables that exist in both the base and compare datasets. These are the variables PROC COMPARE will analyze for value differences.
- Variables in Base Dataset Only: Highlights variables present only in the base dataset and not in the compare dataset. This is useful for identifying missing variables in the comparison dataset.
- Variables in Compare Dataset Only: Conversely, this lists variables found exclusively in the compare dataset, indicating potentially extra or unexpected variables.
Observation Summary: Analyzing Row-Level Differences
The “Observation Summary” focuses on comparing the observations (rows) between the two datasets:
- Observations in Common: Indicates the total number of observations present in both datasets.
- Observations with Equal Values: Counts observations where all corresponding variable values are identical in both datasets. This signifies data consistency across these rows.
- Observations with Unequal Values: Crucially, this highlights the number of observations where at least one variable value differs between the datasets. This pinpoints areas of data inconsistency that require closer inspection.
{width=835 height=358}Values Comparison Summary and Details
The “Values Comparison Summary” and subsequent detail sections provide granular insights into the nature of value differences:
- Variables with All Values Exactly Equal: Lists variables where, across all compared observations, the values are identical in both datasets.
- Variables with Some Values Unequal: Identifies variables where discrepancies exist in at least one observation. This is a key indicator of data inconsistencies within specific variables.
The “Values Comparison Details” (often appearing in subsequent output sections) then drills down to the observation level, showing precisely which observations and variables have differing values. This detailed output is invaluable for pinpointing and rectifying data discrepancies.
{width=736 height=405}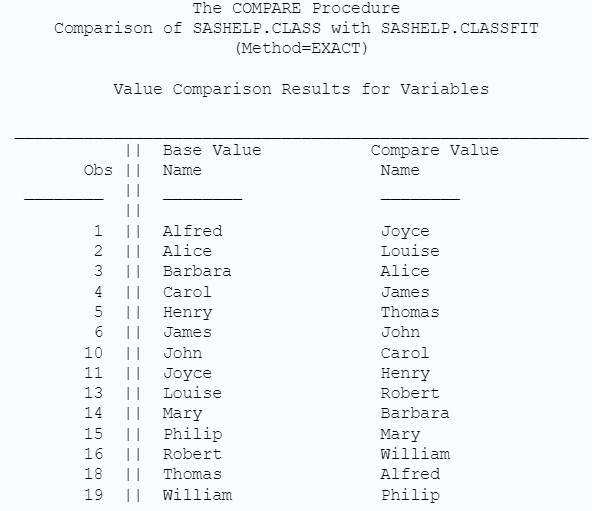{width=592 height=511}Focusing on Specific Variables with the VAR Statement
In scenarios where you are only interested in comparing a subset of variables, PROC COMPARE offers the VAR statement. This allows you to specify the variables you want to include in the comparison, streamlining the output and focusing on relevant data points. For instance, to compare only the “name” variable in our example datasets:
proc compare base = sashelp.class compare = sashelp.classfit; var name; run;While the initial dataset and variable summaries will still reflect the overall dataset structures, the crucial “Value Comparison Results” will now be limited to the “name” variable, providing a targeted comparison.
Structure-Only Comparisons: Utilizing the NOVALUES Option
Sometimes, the primary concern is verifying the structural integrity of datasets – ensuring they have the same variables, data types, and general schema – without delving into value-level comparisons. The NOVALUES option in PROC COMPARE is designed for this purpose. Combined with the LISTVAR option, it becomes a powerful tool for structural validation. LISTVAR specifically requests a listing of variables that are present in only one of the datasets.
proc compare base = sashelp.class compare = sashelp.classfit novalues listvar; run;By using NOVALUES, you instruct SAS to bypass the value comparison sections, focusing solely on the dataset and variable summaries. This is particularly useful in data integration processes or when validating data schemas against predefined templates.
In conclusion, PROC COMPARE is an indispensable tool within SAS for anyone working with data. Its ability to dissect and highlight both similarities and differences between datasets makes it invaluable for data quality control, data validation, and understanding data transformations. By mastering the syntax and interpreting the output sections of PROC COMPARE, SAS users can confidently ensure data accuracy and derive meaningful insights from comparative data analysis.