Discover How To Compare Two Tables In Oracle Sql effectively with COMPARE.EDU.VN. This guide offers comprehensive methods, from using built-in tools to alternative techniques, ensuring accurate schema comparisons and data consistency checks. Learn how to use SQL Developer, data comparison strategies, and schema validation approaches.
1. Understanding the Need to Compare Tables in Oracle SQL
Comparing tables in Oracle SQL is crucial for various reasons, encompassing data integrity, schema validation, and database synchronization. Whether you’re validating database migrations, ensuring consistency between environments, or auditing schema changes, understanding how to effectively compare tables is essential. This section introduces why comparing tables is important and the common scenarios where this task becomes necessary.
1.1. Why is Table Comparison Important?
Table comparison is vital for maintaining data integrity and consistency across different environments. It helps in identifying discrepancies that may arise due to data corruption, incomplete migrations, or unauthorized changes. Comparing tables ensures that the schema and data are synchronized, which is crucial for application stability and reliability.
1.2. Common Scenarios for Comparing Tables
Several scenarios necessitate comparing tables in Oracle SQL:
- Database Migrations: Verifying that the data and schema are correctly migrated from an old database to a new one.
- Environment Synchronization: Ensuring that development, testing, and production environments have identical table structures and data.
- Schema Validation: Validating that the table schema matches the expected structure after applying changes or updates.
- Auditing: Auditing changes made to tables to identify any unauthorized modifications or data inconsistencies.
- Data Reconciliation: Reconciling data between different databases to ensure consistency.
2. Using Oracle SQL Developer to Compare Tables
Oracle SQL Developer provides a built-in tool called “Database Diff” that allows you to compare database schemas, including tables, indexes, constraints, and other database objects. This section details how to use the Database Diff tool to compare two tables effectively, focusing on schema-only comparisons.
2.1. Accessing the Database Diff Tool
The Database Diff tool can be accessed through the “Tools” menu in Oracle SQL Developer. Navigate to Tools -> Database Diff to open the Database Diff wizard.
2.2. Configuring the Comparison
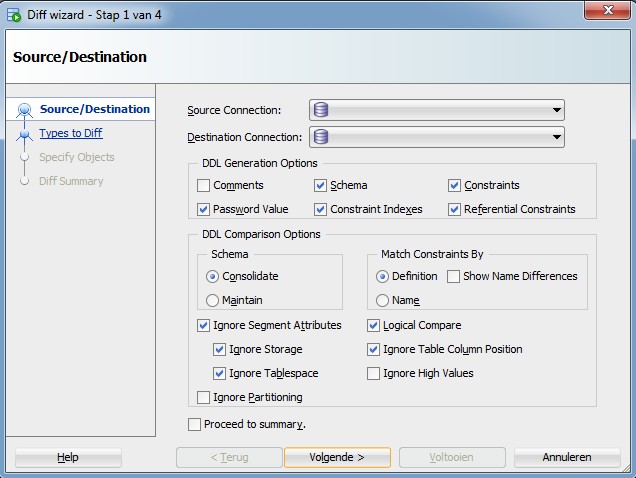
Once the Database Diff wizard is open, you need to configure the comparison by specifying the source and target databases.
- Source Database: Select the source database connection from the dropdown list or create a new connection if necessary. This is the database you are comparing from.
- Target Database: Select the target database connection. This is the database you are comparing to.
- Comparison Options: Choose the objects to compare. For comparing tables, ensure that “Tables” is checked. You can also select other related objects like “Indexes,” “Constraints,” and “Triggers” as needed.
2.3. Excluding Data from the Comparison
To compare only the schema (tables, constraints, etc.) and exclude the data, you need to configure the comparison settings accordingly. Here’s how:
- Object Filters: In the Database Diff wizard, navigate to the “Filters” tab.
- Table Filters: Expand the “Tables” node and select the tables you want to compare.
- Exclude Data: Ensure that the option to exclude data from the comparison is selected. This option may be labeled as “Compare Schema Only” or “Ignore Data.”
By excluding data, the Database Diff tool will only compare the table structures, indexes, constraints, and other schema-related attributes, ignoring the actual data within the tables.
2.4. Running the Comparison
After configuring the comparison settings, click the “Compare” button to start the comparison process. Oracle SQL Developer will analyze the schemas of the source and target databases and identify any differences.
2.5. Analyzing the Differences
Once the comparison is complete, the Database Diff tool will display a detailed report of the differences between the two schemas. The report is organized in a tree-like structure, allowing you to drill down and examine the differences at a granular level.
- Schema Differences: The report highlights any differences in the table structures, such as column names, data types, constraints, and indexes.
- Object Differences: You can view the DDL (Data Definition Language) statements for each object and compare them side-by-side to understand the exact differences.
- Generating Synchronization Scripts: The Database Diff tool can generate synchronization scripts to apply the changes from the source database to the target database. This helps in synchronizing the schemas and ensuring consistency.
3. Alternative Methods for Comparing Tables
If the Database Diff tool in Oracle SQL Developer is not suitable for your needs, or if you encounter performance issues with large datasets, alternative methods can be used to compare tables in Oracle SQL. This section explores several alternative techniques, including exporting schemas, using SQL queries, and leveraging third-party tools.
3.1. Exporting Schemas for Comparison
One alternative approach is to export the schemas of the two databases into separate files and then compare those files using a text comparison tool. This method allows you to focus solely on the schema definitions without being burdened by the data.
3.1.1. Exporting the Schema using expdp
The expdp (Data Pump Export) utility in Oracle SQL can be used to export the schema of a database. You can specify the CONTENT=METADATA_ONLY parameter to export only the schema metadata without the data.
expdp system/password@database_name schemas=SCHEMA_NAME directory=EXPORT_DIR dumpfile=schema_metadata.dmp logfile=schema_metadata.log content=METADATA_ONLYsystem/password@database_name: Replace with your database connection details.schemas=SCHEMA_NAME: Replace with the name of the schema you want to export.directory=EXPORT_DIR: Replace with the name of the directory object where the dump file will be stored.dumpfile=schema_metadata.dmp: The name of the dump file.logfile=schema_metadata.log: The name of the log file.content=METADATA_ONLY: Specifies that only metadata (schema) should be exported.
3.1.2. Extracting DDL Statements
After exporting the schema, you can extract the DDL (Data Definition Language) statements for the tables using the DBMS_METADATA package.
SET LONG 64000
SET PAGESIZE 0
SET LINESIZE 300
SPOOL table_ddl.sql
DECLARE
v_ddl CLOB;
BEGIN
FOR rec IN (SELECT table_name FROM user_tables) LOOP
v_ddl := DBMS_METADATA.GET_DDL('TABLE', rec.table_name, USER);
DBMS_OUTPUT.PUT_LINE(v_ddl);
END LOOP;
END;
/
SPOOL OFFThis script generates a SQL file containing the DDL statements for all tables in the current schema.
3.1.3. Comparing the Exported Files
Once you have the DDL statements in separate files, you can use a text comparison tool like diff (on Linux/Unix) or Notepad++ (on Windows) to compare the files and identify any differences. These tools highlight the lines that are different between the two files, making it easier to spot discrepancies in the schema definitions.
3.2. Using SQL Queries for Table Comparison
SQL queries can be used to compare the structure and data of two tables. This method is particularly useful for identifying specific differences or for automating the comparison process.
3.2.1. Comparing Table Structures
To compare the structure of two tables, you can query the USER_TAB_COLUMNS view, which contains information about the columns in each table.
SELECT table_name, column_name, data_type, data_length, nullable
FROM user_tab_columns
WHERE table_name IN ('TABLE1', 'TABLE2')
ORDER BY table_name, column_id;Compare the results for both tables to identify any differences in column names, data types, lengths, or nullability constraints.
3.2.2. Comparing Data using MINUS Operator
The MINUS operator can be used to find rows that exist in one table but not in another.
SELECT * FROM TABLE1
MINUS
SELECT * FROM TABLE2;
SELECT * FROM TABLE2
MINUS
SELECT * FROM TABLE1;The first query returns rows that are in TABLE1 but not in TABLE2, while the second query returns rows that are in TABLE2 but not in TABLE1.
3.2.3. Comparing Data using EXCEPT Operator
The EXCEPT operator is similar to MINUS but is available in some database systems.
SELECT * FROM TABLE1
EXCEPT
SELECT * FROM TABLE2;
SELECT * FROM TABLE2
EXCEPT
SELECT * FROM TABLE1;These queries will identify rows that are unique to each table.
3.2.4. Comparing Data using FULL OUTER JOIN
A FULL OUTER JOIN can be used to compare data and identify differences by joining the tables on their primary key or a unique identifier.
SELECT
COALESCE(T1.ID, T2.ID) AS ID,
T1.COLUMN1 AS T1_COLUMN1,
T2.COLUMN1 AS T2_COLUMN1,
T1.COLUMN2 AS T1_COLUMN2,
T2.COLUMN2 AS T2_COLUMN2
FROM
TABLE1 T1
FULL OUTER JOIN
TABLE2 T2 ON T1.ID = T2.ID
WHERE
T1.ID IS NULL OR T2.ID IS NULL OR T1.COLUMN1 <> T2.COLUMN1 OR T1.COLUMN2 <> T2.COLUMN2;This query returns rows where the data in the specified columns is different between the two tables, or where a row exists in one table but not the other.
3.3. Using Third-Party Tools for Table Comparison
Several third-party tools are available for comparing tables in Oracle SQL. These tools often provide advanced features such as graphical interfaces, detailed comparison reports, and synchronization capabilities.
3.3.1. Toad for Oracle
Toad for Oracle is a popular database development and administration tool that includes a schema comparison feature. It allows you to compare schemas, tables, and data, and generate synchronization scripts to update the target database.
3.3.2. DBeaver
DBeaver is a free, open-source database tool that supports multiple database systems, including Oracle. It provides a schema comparison feature that allows you to compare tables and generate DDL scripts to synchronize the schemas.
3.3.3. ApexSQL Diff
ApexSQL Diff is a commercial tool specifically designed for comparing and synchronizing database schemas. It supports Oracle and other database systems and provides advanced features such as object filtering, dependency analysis, and change history tracking.
4. Strategies for Effective Table Comparison
To ensure accurate and efficient table comparisons, several strategies can be employed. This section outlines best practices for preparing data, handling large tables, and automating the comparison process.
4.1. Preparing Data for Comparison
Before comparing tables, it is essential to prepare the data to ensure accurate results. This includes cleaning and transforming the data to remove inconsistencies and ensure comparability.
4.1.1. Data Cleansing
Data cleansing involves removing or correcting inaccurate, incomplete, or irrelevant data. Common data cleansing tasks include:
- Removing Duplicate Rows: Identifying and removing duplicate rows that may skew the comparison results.
- Handling Null Values: Standardizing null values to ensure consistent comparison.
- Data Type Conversion: Converting data types to match between the tables being compared.
- Trimming Whitespace: Removing leading or trailing whitespace from text fields.
4.1.2. Data Transformation
Data transformation involves converting data from one format to another to ensure comparability. Common data transformation tasks include:
- Date Formatting: Standardizing date formats to ensure consistent comparison.
- String Normalization: Converting strings to a consistent case (e.g., uppercase or lowercase) to avoid case-sensitive differences.
- Encoding Conversion: Converting character encodings to ensure proper comparison of text data.
4.2. Handling Large Tables
Comparing large tables can be challenging due to performance limitations. Several techniques can be used to optimize the comparison process for large tables.
4.2.1. Partitioning
Partitioning involves dividing a large table into smaller, more manageable pieces. This allows you to compare the partitions separately, reducing the amount of data that needs to be processed at one time.
4.2.2. Sampling
Sampling involves selecting a subset of the data from each table for comparison. This can significantly reduce the amount of data that needs to be processed, but it may also reduce the accuracy of the comparison.
4.2.3. Indexing
Creating indexes on the columns used for comparison can improve the performance of the comparison queries. Indexes allow the database to quickly locate the rows that need to be compared, reducing the amount of time required to perform the comparison.
4.3. Automating the Comparison Process
Automating the table comparison process can save time and reduce the risk of human error. Several tools and techniques can be used to automate the comparison process.
4.3.1. SQL Scripts
SQL scripts can be used to automate the comparison process by executing a series of SQL queries to compare the table structures and data. These scripts can be scheduled to run automatically at regular intervals.
4.3.2. Scripting Languages
Scripting languages such as Python or Perl can be used to automate the comparison process by interacting with the database and executing SQL queries. These scripts can be customized to perform specific comparison tasks and generate detailed reports.
4.3.3. Third-Party Tools
Third-party tools often provide features for automating the table comparison process. These tools can be configured to run comparisons automatically at scheduled intervals and generate reports of any differences.
5. Key Considerations for Accurate Table Comparison
Ensuring accurate table comparisons requires careful consideration of various factors. This section highlights key considerations such as data types, character sets, constraints, and indexes.
5.1. Data Types
Data type differences can lead to inaccurate comparison results. Ensure that the data types of the columns being compared are compatible. If necessary, convert the data types to match before performing the comparison.
5.2. Character Sets
Character set differences can cause issues when comparing text data. Ensure that the character sets of the tables being compared are compatible. If necessary, convert the character sets to match before performing the comparison.
5.3. Constraints
Constraints, such as primary keys, foreign keys, and unique constraints, can affect the comparison results. Ensure that the constraints are consistent between the tables being compared. If necessary, add or remove constraints to match the table structures.
5.4. Indexes
Indexes can improve the performance of the comparison queries, but they can also affect the comparison results. Ensure that the indexes are consistent between the tables being compared. If necessary, create or drop indexes to match the table structures.
6. Practical Examples of Table Comparison
To illustrate the concepts discussed, this section provides practical examples of comparing tables in Oracle SQL using different methods.
6.1. Example 1: Comparing Table Structures using SQL Queries
Suppose you have two tables, EMPLOYEES_A and EMPLOYEES_B, and you want to compare their structures.
SELECT table_name, column_name, data_type, data_length, nullable
FROM user_tab_columns
WHERE table_name IN ('EMPLOYEES_A', 'EMPLOYEES_B')
ORDER BY table_name, column_id;Compare the results for both tables to identify any differences in column names, data types, lengths, or nullability constraints.
6.2. Example 2: Comparing Data using the MINUS Operator
Suppose you want to find the rows that exist in EMPLOYEES_A but not in EMPLOYEES_B.
SELECT * FROM EMPLOYEES_A
MINUS
SELECT * FROM EMPLOYEES_B;This query returns the rows that are unique to EMPLOYEES_A.
6.3. Example 3: Comparing Data using a FULL OUTER JOIN
Suppose you want to compare the data in EMPLOYEES_A and EMPLOYEES_B and identify any differences.
SELECT
COALESCE(A.EMPLOYEE_ID, B.EMPLOYEE_ID) AS EMPLOYEE_ID,
A.FIRST_NAME AS A_FIRST_NAME,
B.FIRST_NAME AS B_FIRST_NAME,
A.LAST_NAME AS A_LAST_NAME,
B.LAST_NAME AS B_LAST_NAME
FROM
EMPLOYEES_A A
FULL OUTER JOIN
EMPLOYEES_B B ON A.EMPLOYEE_ID = B.EMPLOYEE_ID
WHERE
A.EMPLOYEE_ID IS NULL OR B.EMPLOYEE_ID IS NULL OR A.FIRST_NAME <> B.FIRST_NAME OR A.LAST_NAME <> B.LAST_NAME;This query returns the rows where the data in the specified columns is different between the two tables, or where a row exists in one table but not the other.
7. Troubleshooting Common Issues
When comparing tables in Oracle SQL, you may encounter various issues. This section provides solutions to common problems, such as performance issues, data type mismatches, and character set incompatibilities.
7.1. Performance Issues
Performance issues can arise when comparing large tables. To improve performance:
- Use Partitioning: Divide large tables into smaller partitions for comparison.
- Create Indexes: Create indexes on the columns used for comparison.
- Use Sampling: Select a subset of the data for comparison.
- Optimize Queries: Ensure that the comparison queries are optimized.
7.2. Data Type Mismatches
Data type mismatches can lead to inaccurate comparison results. To resolve data type mismatches:
- Convert Data Types: Convert the data types of the columns being compared to match.
- Use Appropriate Comparison Operators: Use comparison operators that are appropriate for the data types being compared.
- Handle Null Values: Standardize null values to ensure consistent comparison.
7.3. Character Set Incompatibilities
Character set incompatibilities can cause issues when comparing text data. To resolve character set incompatibilities:
- Convert Character Sets: Convert the character sets of the tables being compared to match.
- Use Appropriate Collation: Use a collation that is appropriate for the character sets being compared.
- Normalize Text Data: Normalize text data to remove any inconsistencies in character encoding.
8. Ensuring Data Consistency and Integrity
Maintaining data consistency and integrity is critical in database management. Consistent data ensures accuracy and reliability across all applications and systems. This section outlines the significance of data consistency and the best practices for ensuring data integrity during and after table comparisons.
8.1. The Importance of Data Consistency
Data consistency refers to the uniformity and accuracy of data across all instances within a database. Inconsistent data can lead to flawed decision-making, operational inefficiencies, and compliance issues. Ensuring data consistency helps organizations:
- Make Informed Decisions: Accurate data leads to better insights and strategic decisions.
- Improve Operational Efficiency: Consistent data reduces errors and rework.
- Ensure Regulatory Compliance: Accurate records are essential for meeting legal and regulatory requirements.
- Enhance Customer Satisfaction: Reliable data ensures consistent service and interactions.
8.2. Best Practices for Ensuring Data Integrity
Data integrity involves maintaining the accuracy, completeness, and reliability of data throughout its lifecycle. Following these best practices helps ensure data integrity:
- Define Data Standards: Establish clear standards for data formats, types, and validation rules.
- Implement Data Validation: Implement validation checks at the point of data entry to prevent incorrect data from entering the system.
- Use Constraints: Employ database constraints (e.g., primary keys, foreign keys, unique constraints) to enforce data relationships and prevent inconsistencies.
- Regular Backups: Conduct regular backups to ensure data can be restored in case of corruption or loss.
- Audit Trails: Maintain audit trails to track changes made to the data, providing a record of who changed what and when.
- Data Reconciliation: Regularly reconcile data between different systems to identify and resolve discrepancies.
9. Advanced Techniques for Table Comparison
For complex scenarios, advanced techniques can provide more granular control and insight into table comparisons. This section explores advanced methods such as using checksums, temporal data comparisons, and custom comparison functions.
9.1. Using Checksums for Data Validation
Checksums are a method of verifying data integrity by calculating a hash value of the data and comparing it across different tables or systems. If the checksums match, it indicates that the data is likely the same.
9.1.1. Calculating Checksums
Oracle provides built-in functions like DBMS_UTILITY.GET_HASH_VALUE to calculate checksums for table rows.
SELECT
TABLE_NAME,
COUNT(*),
SUM(DBMS_UTILITY.GET_HASH_VALUE(COLUMN1, 1, 0)) AS CHECKSUM_COLUMN1,
SUM(DBMS_UTILITY.GET_HASH_VALUE(COLUMN2, 1, 0)) AS CHECKSUM_COLUMN2
FROM
YOUR_TABLE
GROUP BY
TABLE_NAME;Compare the checksum values between the tables to identify any discrepancies.
9.1.2. Benefits of Using Checksums
- Efficiency: Checksums provide a quick way to validate data without comparing every row.
- Reduced Resource Usage: Calculating checksums is less resource-intensive than comparing entire datasets.
- Early Detection: Checksums can detect data corruption or inconsistencies early in the process.
9.2. Temporal Data Comparisons
Temporal data includes a time dimension, tracking changes over time. Comparing temporal data involves analyzing how data evolves and identifying differences in historical records.
9.2.1. Using Temporal Clauses
Oracle supports temporal clauses like AS OF TIMESTAMP to query data as it existed at a specific point in time.
SELECT
*
FROM
YOUR_TABLE
AS OF TIMESTAMP SYSTIMESTAMP - INTERVAL '1' DAY;Compare the data at different points in time to identify changes and inconsistencies.
9.2.2. Analyzing Historical Data
Compare historical data to current data to identify trends, anomalies, and changes in data values. This helps in understanding how data has evolved over time.
9.3. Custom Comparison Functions
For specialized comparison needs, custom functions can be created to compare data based on specific criteria. This allows for more flexible and tailored comparisons.
9.3.1. Creating Custom Functions
Custom functions can be created in PL/SQL to compare data based on specific business rules or logic.
CREATE OR REPLACE FUNCTION COMPARE_DATA (
VALUE1 IN VARCHAR2,
VALUE2 IN VARCHAR2
) RETURN NUMBER IS
BEGIN
IF VALUE1 = VALUE2 THEN
RETURN 1; -- Data is the same
ELSE
RETURN 0; -- Data is different
END IF;
END;
/9.3.2. Using Custom Functions in Queries
Custom functions can be used in SQL queries to compare data based on the defined logic.
SELECT
COLUMN1,
COLUMN2,
COMPARE_DATA(COLUMN1, COLUMN2) AS DATA_MATCH
FROM
YOUR_TABLE;10. Table Comparison in Data Warehousing
Data warehousing involves integrating data from multiple sources into a central repository for analysis and reporting. Comparing tables in a data warehousing environment is essential for ensuring data quality and consistency.
10.1. The Role of Table Comparison in Data Warehousing
Table comparison plays a critical role in data warehousing by ensuring that data is accurately transformed and loaded into the warehouse. It helps in:
- Validating ETL Processes: Ensuring that data is correctly extracted, transformed, and loaded into the warehouse.
- Identifying Data Quality Issues: Detecting data inconsistencies, errors, and anomalies in the warehouse.
- Ensuring Data Consistency: Maintaining consistent data across different dimensions and fact tables.
- Supporting Data Governance: Implementing data governance policies and ensuring data integrity.
10.2. Techniques for Comparing Tables in Data Warehouses
Several techniques can be used to compare tables in data warehouses, including:
- Data Profiling: Analyzing data to identify patterns, anomalies, and inconsistencies.
- Data Reconciliation: Comparing data between source systems and the data warehouse to ensure accuracy.
- Data Validation: Implementing validation checks to ensure that data meets defined standards and rules.
- Change Data Capture (CDC): Tracking changes in source systems and applying them to the data warehouse.
10.3. Tools for Data Warehousing Table Comparison
Various tools are available for comparing tables in data warehousing environments, including:
- Informatica Data Quality: Provides data profiling, data cleansing, and data validation capabilities.
- IBM InfoSphere Information Analyzer: Analyzes data to identify data quality issues and inconsistencies.
- Talend Data Integration: Integrates data from multiple sources and provides data quality features.
11. Best Practices for Performance Optimization
Optimizing performance is crucial when comparing tables, especially in large databases. Implementing the following best practices can significantly improve the speed and efficiency of table comparisons.
11.1. Indexing Strategies
Proper indexing can dramatically reduce the time required to compare tables by allowing the database to quickly locate and retrieve relevant data.
11.1.1. Identifying Columns for Indexing
Identify the columns frequently used in comparison queries (e.g., join columns, filter columns) and create indexes on these columns.
11.1.2. Types of Indexes
- B-Tree Indexes: Suitable for most general-purpose queries.
- Bitmap Indexes: Effective for low-cardinality columns (e.g., columns with a limited number of distinct values).
- Function-Based Indexes: Useful for indexing the results of functions or expressions used in queries.
11.2. Query Optimization Techniques
Optimizing SQL queries can significantly improve the performance of table comparisons.
11.2.1. Using Explain Plans
Use the EXPLAIN PLAN statement to analyze the execution plan of a query and identify potential performance bottlenecks.
11.2.2. Rewriting Queries
Rewrite complex queries to simplify them and improve their performance. Use techniques such as:
- Avoiding Subqueries: Replace subqueries with joins where possible.
- Using Hints: Use hints to guide the optimizer in choosing the best execution plan.
- Filtering Early: Apply filters as early as possible in the query to reduce the amount of data processed.
11.3. Resource Management
Proper resource management can prevent performance issues during table comparisons.
11.3.1. Monitoring System Resources
Monitor CPU, memory, and I/O usage during table comparisons to identify resource bottlenecks.
11.3.2. Allocating Sufficient Resources
Ensure that the database server has sufficient resources to handle the table comparison workload. Increase memory, CPU, or I/O capacity as needed.
12. Future Trends in Table Comparison
As technology evolves, new trends and innovations are emerging in the field of table comparison. This section explores future trends such as AI-driven comparison, cloud-based solutions, and real-time data validation.
12.1. AI-Driven Table Comparison
Artificial intelligence (AI) and machine learning (ML) are being used to automate and enhance table comparison processes.
12.1.1. Anomaly Detection
AI algorithms can detect anomalies and inconsistencies in data by analyzing patterns and trends. This helps in identifying data quality issues that may not be apparent through traditional comparison methods.
12.1.2. Automated Data Profiling
AI can automate the data profiling process by analyzing data characteristics and identifying potential issues. This saves time and effort compared to manual data profiling.
12.2. Cloud-Based Table Comparison Solutions
Cloud-based solutions offer scalable and cost-effective options for table comparison.
12.2.1. Scalability
Cloud platforms provide on-demand scalability, allowing you to easily scale resources up or down as needed for table comparisons.
12.2.2. Cost-Effectiveness
Cloud-based solutions eliminate the need for upfront investments in hardware and software, making them a cost-effective option for table comparison.
12.3. Real-Time Data Validation
Real-time data validation involves continuously monitoring data for errors and inconsistencies as it is being processed.
12.3.1. Continuous Monitoring
Real-time data validation systems continuously monitor data streams for anomalies and inconsistencies.
12.3.2. Automated Alerts
Automated alerts are triggered when data quality issues are detected, allowing for prompt intervention and resolution.
13. Conclusion: Streamlining Table Comparisons in Oracle SQL
In summary, comparing tables in Oracle SQL is a critical task for maintaining data integrity, validating schema changes, and ensuring data consistency across environments. Whether you use Oracle SQL Developer’s built-in tools, alternative methods like exporting schemas, or third-party solutions, the key is to choose the approach that best fits your specific needs and technical environment. By following the strategies and best practices outlined in this guide, you can effectively compare tables, identify discrepancies, and maintain the quality and reliability of your data.
Are you struggling to compare data across your databases and ensure accuracy? Visit compare.edu.vn for comprehensive guides, tool comparisons, and expert advice on streamlining your data comparison processes. Contact us at 333 Comparison Plaza, Choice City, CA 90210, United States, or Whatsapp: +1 (626) 555-9090. Let us help you make informed decisions and maintain the integrity of your data.
14. FAQ Section: Addressing Common Questions About Table Comparison
This FAQ section addresses common questions related to comparing tables in Oracle SQL, providing clear and concise answers to help you better understand the process.
Q1: What is the best way to compare two tables in Oracle SQL?
The best approach depends on your specific needs. Oracle SQL Developer’s Database Diff tool is suitable for schema comparisons. SQL queries are useful for data comparisons, and third-party tools offer advanced features.
Q2: How can I exclude data from the table comparison in Oracle SQL Developer?
In the Database Diff wizard, navigate to the “Filters” tab, expand the “Tables” node, select the tables you want to compare, and ensure that the option to exclude data is selected.
Q3: What is the MINUS operator used for in table comparison?
The MINUS operator is used to find rows that exist in one table but not in another. It returns the rows that are unique to the first table in the query.
Q4: How can I compare the structures of two tables using SQL queries?
You can query the USER_TAB_COLUMNS view to compare the structures of two tables. This view contains information about the columns in each table, such as column names, data types, and lengths.
Q5: What are the benefits of using checksums for data validation?
Checksums provide a quick way to validate data without comparing every row, reduce resource usage, and detect data corruption or inconsistencies early in the process.
Q6: How can I handle large tables during table comparison to improve performance?
To handle large tables, you can use partitioning, sampling, and indexing. Partitioning involves dividing the table into smaller pieces, sampling involves selecting a subset of the data, and indexing involves creating indexes on the columns used for comparison.
Q7: What is the role of table comparison in data warehousing?
Table comparison plays a critical role in data warehousing by ensuring that data is accurately transformed and loaded into the warehouse, identifying data quality issues, and ensuring data consistency.
Q8: What are some common data quality issues that can be identified through table comparison?
Common data quality issues include inconsistencies, errors, anomalies, and duplicate rows. Table comparison can help detect these issues and ensure data accuracy.
Q9: How can I automate the table comparison process in Oracle SQL?
You can automate the table comparison process using SQL scripts, scripting languages such as Python or Perl, or third-party tools that provide features for automating comparisons at scheduled intervals.
Q10: What are some future trends in table comparison?
Future trends include AI-driven comparison, cloud-based solutions, and real-time data validation. These trends aim to enhance the efficiency, accuracy, and scalability of table comparison processes.