Comparing ranked data from two or more groups can be challenging. With numerous potential comparisons and limited data, efficient aggregation is key. This article outlines a permutation test approach, offering a flexible solution when standard statistical tests might not be suitable.
Defining the Functions for Comparison
Two crucial functions form the foundation of this method:
1. The Voting Function
This function assigns scores to rankings within each group, allowing for the combination of individual rankings into a single group score. A simple approach assigns 1 point to the top-ranked item and 0 to others. However, to capture more information, consider assigning decreasing points based on rank (e.g., 1 point for first, 2 for second, and so on). The chosen voting function significantly impacts the final results.
2. The Comparison Function
This function compares the aggregated scores between groups. Since these scores are vectors, a suitable norm of their difference (e.g., the L1 or L2 norm) serves as a robust comparison metric. The choice of norm influences the sensitivity of the comparison to differences in rankings.
Implementing the Permutation Test
-
Calculate the Test Statistic: Apply the voting function to each item across both groups, resulting in two vectors representing average scores. Then, use the comparison function to quantify the difference between these vectors. This difference is your initial test statistic.
-
Generate the Null Distribution: To understand the significance of the test statistic, create a null distribution by repeatedly shuffling the combined data of both groups. Randomly assign observations to each group, maintaining the original group sizes. Calculate the test statistic for each shuffled sample, repeating this process numerous times (e.g., 1000 iterations).
-
Calculate the p-value: The resulting distribution of test statistics from the shuffled samples represents the null distribution – the distribution expected if there’s no real difference between the groups. Compare your original test statistic to this distribution to determine the p-value. The p-value represents the probability of observing a test statistic as extreme as or more extreme than yours, assuming no difference between groups. A low p-value suggests a statistically significant difference.
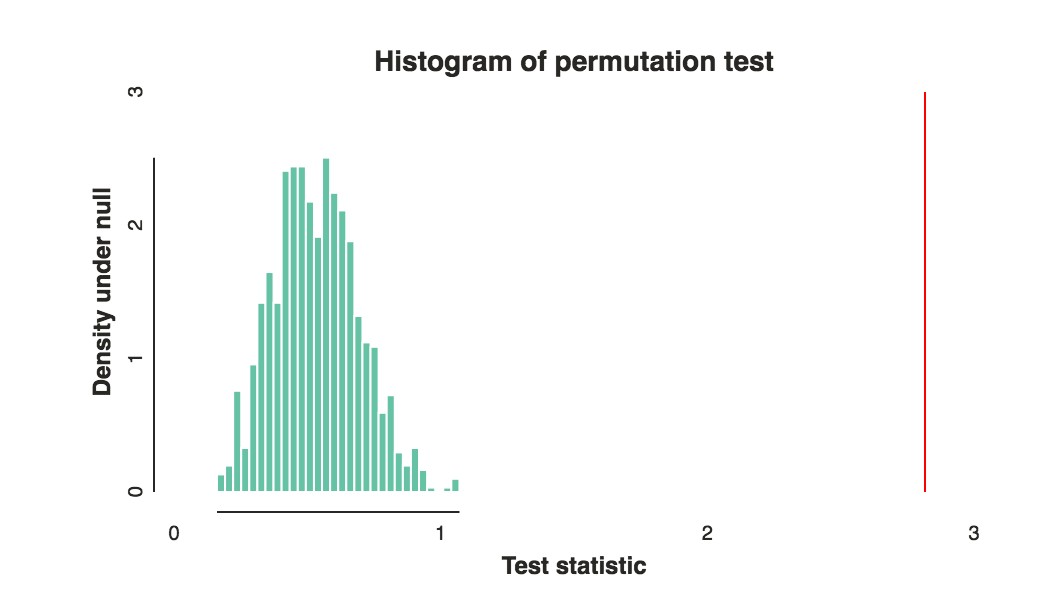
Example of a permutation test using the L1 norm.
The same data using the L2 norm, demonstrating the impact of choosing different comparison functions.
Choosing the Right Functions
Selecting appropriate voting and comparison functions is crucial for the test’s power to detect real differences. The optimal choice depends on the specific research question and data characteristics. The L1 and L2 norms offer good starting points for the comparison function. Prior knowledge about potential differences between groups can inform the choice of functions. Importantly, these decisions should be made before running the test to avoid cherry-picking and ensure the validity of the results.
Conclusion
The permutation test provides a flexible and powerful approach to comparing ranked data when traditional methods might fall short. By carefully defining voting and comparison functions and generating a null distribution through permutations, researchers can robustly assess the significance of observed differences in rankings. Remember to prioritize careful consideration of the research question, data characteristics, and potential sources of bias when applying this method.