Comparing datasets is crucial for data-driven decision-making, ensuring data quality and uncovering valuable insights. COMPARE.EDU.VN provides the tools and knowledge necessary to effectively compare datasets, enabling you to make informed decisions. Learn How To Compare Datasets with statistical tests, data visualization, and exploratory data analysis for similarity and actionable insights.
1. Understanding the Fundamentals of Dataset Comparison
Datasets are the bedrock of data science and machine learning projects, and their quality directly impacts the accuracy and reliability of results. In 2023, a staggering 74% of organizations reported that poor data quality affected over 25% of their revenue, according to research. This underscores the critical need for robust dataset comparison techniques.
Dataset comparison involves evaluating two or more datasets to identify similarities, differences, and potential issues. This process helps determine which dataset is most suitable for a specific task, ensures data quality, and uncovers hidden patterns. Effective dataset comparison goes beyond simple visual inspection; it requires a systematic approach that incorporates statistical analysis, data visualization, and domain expertise. COMPARE.EDU.VN provides comprehensive resources to guide you through each step, ensuring a thorough and insightful comparison.
1.1. Defining the Scope of Comparison
Before diving into the technical aspects, it’s crucial to define the scope of your dataset comparison. This involves understanding the purpose of the comparison, identifying the key features to analyze, and establishing clear evaluation criteria. What specific questions are you trying to answer? Are you looking for discrepancies in data quality, differences in data distribution, or variations in specific metrics?
Consider the following aspects when defining the scope:
- Data Types: Are you comparing numerical, categorical, or textual data?
- Data Sources: Where did the datasets originate from? Are they from different sensors, surveys, or databases?
- Data Size: How large are the datasets? Are they comparable in size, or is one significantly larger than the other?
- Data Relevance: How relevant are the datasets to your specific goals? Do they contain the information you need to answer your research questions or solve your business problems?
By clearly defining the scope, you can focus your efforts on the most relevant aspects of the datasets and avoid wasting time on irrelevant comparisons.
1.2. Key Metrics for Dataset Comparison
Selecting the right metrics is essential for quantifying the similarities and differences between datasets. The choice of metrics depends on the data types and the specific goals of the comparison. Here are some commonly used metrics:
- Statistical Measures:
- Mean: The average value of a numerical feature.
- Median: The middle value of a numerical feature when the data is sorted.
- Standard Deviation: A measure of the spread or variability of a numerical feature.
- Variance: The square of the standard deviation.
- Percentiles: Values that divide the data into 100 equal parts (e.g., 25th percentile, 75th percentile).
- Distribution Metrics:
- Skewness: A measure of the asymmetry of a distribution.
- Kurtosis: A measure of the “tailedness” of a distribution.
- Kolmogorov-Smirnov Test: A statistical test for comparing the distributions of two datasets.
- Categorical Metrics:
- Frequency Distribution: The number of times each category appears in the dataset.
- Mode: The most frequent category in the dataset.
- Chi-Squared Test: A statistical test for comparing the proportions of different categories in two datasets.
- Data Quality Metrics:
- Completeness: The percentage of missing values in the dataset.
- Accuracy: The degree to which the data is free from errors.
- Consistency: The extent to which the data is consistent across different sources.
- Uniqueness: The number of duplicate records in the dataset.
Consider a scenario where you are comparing two datasets of customer purchase data. You might use the mean and standard deviation to compare the average purchase amount and the variability of purchase amounts in each dataset. You could also use the frequency distribution to compare the popularity of different product categories in the two datasets.
1.3. Data Visualization Techniques for Comparison
Data visualization is a powerful tool for gaining insights into datasets and identifying differences. Visual representations can reveal patterns and anomalies that might be missed by statistical analysis alone. Here are some common data visualization techniques for dataset comparison:
- Histograms: Display the distribution of a numerical feature. Comparing histograms of the same feature in different datasets can reveal differences in shape, center, and spread.
- Boxplots: Summarize the distribution of a numerical feature using quartiles, median, and outliers. Boxplots are useful for comparing the central tendency and variability of different datasets.
- Scatterplots: Show the relationship between two numerical features. Comparing scatterplots of the same features in different datasets can reveal differences in correlation and clustering patterns.
- Bar Charts: Display the frequency distribution of categorical features. Comparing bar charts of the same feature in different datasets can reveal differences in the proportions of different categories.
- Heatmaps: Display the correlation between multiple features. Comparing heatmaps of different datasets can reveal differences in the relationships between variables.
For example, if you are comparing two datasets of website traffic data, you could use histograms to compare the distribution of page load times in each dataset. You could also use scatterplots to compare the relationship between bounce rate and time on page in the two datasets.
1.4. Understanding Data Types and Their Implications
The type of data you are comparing significantly influences the appropriate comparison methods and metrics. Here’s a breakdown of common data types and their implications:
- Numerical Data: Represents quantities or measurements (e.g., age, temperature, income). Numerical data can be further divided into:
- Discrete Data: Represents countable values (e.g., number of customers, number of products).
- Continuous Data: Represents values that can take on any value within a range (e.g., height, weight, temperature).
- Categorical Data: Represents categories or labels (e.g., gender, product category, country). Categorical data can be further divided into:
- Nominal Data: Represents categories with no inherent order (e.g., colors, types of cars).
- Ordinal Data: Represents categories with a meaningful order (e.g., education level, customer satisfaction ratings).
- Textual Data: Represents strings of characters (e.g., customer reviews, product descriptions, social media posts).
Understanding the data types is crucial for selecting appropriate statistical tests and visualization techniques. For example, you would use a t-test to compare the means of two numerical datasets, while you would use a chi-squared test to compare the proportions of different categories in two categorical datasets.
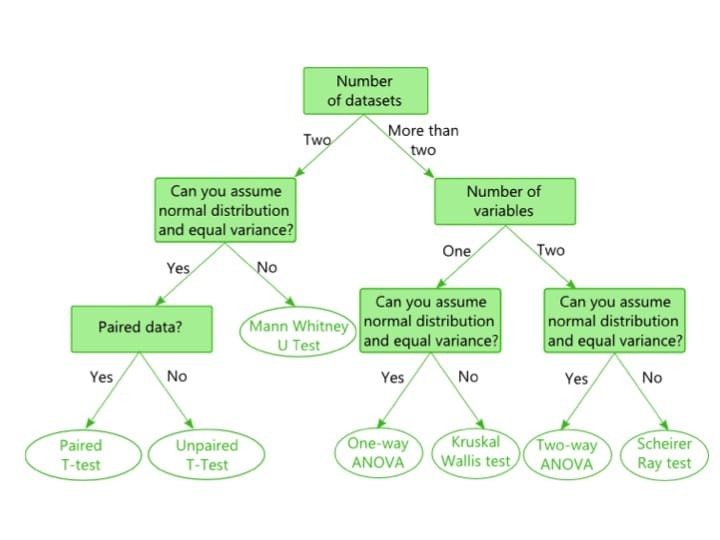 Decision tree for comparing two sets of data
Decision tree for comparing two sets of data
Decision tree visualization aids in strategic dataset comparison.
2. Methods for Comparing Datasets
Several methods can be employed to compare datasets, each with its strengths and weaknesses. The choice of method depends on the specific goals of the comparison, the data types, and the size of the datasets.
2.1. Statistical Tests: Unveiling Significant Differences
Statistical tests are powerful tools for determining whether the differences between two datasets are statistically significant or simply due to random chance. These tests provide a rigorous framework for hypothesis testing and allow you to draw conclusions with a certain level of confidence.
Here are some commonly used statistical tests for dataset comparison:
- T-Test: Used to compare the means of two independent groups. There are different types of t-tests, including:
- Independent Samples T-Test: Used when the two groups are independent of each other.
- Paired Samples T-Test: Used when the two groups are related (e.g., before and after measurements on the same individuals).
- ANOVA (Analysis of Variance): Used to compare the means of three or more groups.
- Chi-Squared Test: Used to compare the proportions of different categories in two or more groups.
- Kolmogorov-Smirnov Test: Used to compare the distributions of two datasets.
- Mann-Whitney U Test: A non-parametric test used to compare the medians of two independent groups.
When selecting a statistical test, it’s crucial to consider the assumptions of the test and whether those assumptions are met by the data. For example, the t-test assumes that the data is normally distributed, while the Mann-Whitney U test does not make this assumption.
2.2. Data Visualization: Spotting Patterns and Anomalies
As mentioned earlier, data visualization is an invaluable tool for dataset comparison. Visual representations can reveal patterns, trends, and anomalies that might be missed by statistical tests alone. By creating insightful visualizations, you can gain a deeper understanding of the datasets and identify potential issues.
Here are some additional data visualization techniques that can be used for dataset comparison:
- Parallel Coordinates Plots: Display multiple features for each data point, allowing you to compare the relationships between features across different datasets.
- Radar Charts: Display multiple features for each data point in a circular format, making it easy to compare the overall profiles of different datasets.
- Violin Plots: Similar to boxplots but also show the probability density of the data, providing a more detailed view of the distribution.
- Word Clouds: Display the frequency of words in textual data, allowing you to compare the topics and themes that are prevalent in different datasets.
When creating data visualizations, it’s essential to choose the appropriate chart type for the data and the message you want to convey. Also, make sure to label the axes clearly and provide a descriptive title for each chart.
2.3. Exploratory Data Analysis (EDA): A Comprehensive Approach
Exploratory Data Analysis (EDA) is a comprehensive approach to analyzing data to understand its characteristics, identify patterns and relationships, and uncover potential issues. EDA is an iterative process that involves data cleaning, data visualization, and statistical analysis.
The key steps in EDA include:
- Data Cleaning: This step involves identifying and correcting errors in the data, such as missing values, outliers, and duplicate records.
- Data Visualization: The process of creating graphs and charts to visualize the data and identify patterns and relationships.
- Statistical Analysis: This involves using statistical tests to quantify the strength of relationships and to identify significant differences between groups.
- Feature Engineering: Creating new features from existing ones to improve the performance of machine learning models.
EDA is a crucial step in any data science project and can be used to compare and evaluate datasets effectively. By performing EDA on each dataset, you can gain a deep understanding of its characteristics and identify potential issues that might affect your analysis.
2.4. Machine Learning Techniques for Dataset Comparison
Machine learning techniques can also be used for dataset comparison, particularly when dealing with large and complex datasets. These techniques can help identify subtle differences between datasets that might be missed by traditional statistical methods.
Here are some machine learning techniques that can be used for dataset comparison:
- Clustering: Grouping similar data points together based on their features. Comparing the clusters formed in different datasets can reveal differences in the underlying structure of the data.
- Classification: Training a model to predict the class label of each data point. Comparing the performance of the model on different datasets can reveal differences in the predictive power of the features.
- Anomaly Detection: Identifying data points that are significantly different from the rest of the data. Comparing the anomalies detected in different datasets can reveal differences in the presence of outliers or unusual patterns.
- Dimensionality Reduction: Reducing the number of features in the dataset while preserving the most important information. Comparing the reduced representations of different datasets can reveal differences in the underlying structure of the data.
For example, you could use clustering to group customers into different segments based on their purchasing behavior. Comparing the customer segments in different datasets can reveal differences in the demographics and preferences of customers in different markets.
3. The Importance of Dataset Comparison
Dataset comparison is not just a technical exercise; it’s a critical step in ensuring the validity and reliability of your data-driven decisions. The benefits of dataset comparison extend across various domains, from scientific research to business intelligence.
3.1. Ensuring Data Quality and Reliability
One of the primary reasons for comparing datasets is to ensure data quality and reliability. By comparing different sources or versions of data, you can identify inconsistencies, errors, and biases that might compromise your analysis.
Consider a scenario where you are collecting data from multiple sensors. Comparing the data from different sensors can help you identify malfunctioning sensors or calibration errors. Similarly, if you are merging data from different databases, comparing the data can help you identify inconsistencies in data formats or coding schemes.
By identifying and correcting data quality issues, you can ensure that your analysis is based on accurate and reliable data. This, in turn, leads to more informed decisions and better outcomes.
3.2. Identifying Trends, Patterns, and Outliers
Dataset comparison can also help you identify trends, patterns, and outliers that might be hidden within the data. By comparing different datasets, you can gain a broader perspective and uncover insights that might not be apparent from analyzing a single dataset.
For example, if you are comparing sales data from different regions, you might identify regional trends in consumer preferences or seasonal patterns in demand. Similarly, if you are comparing patient data from different hospitals, you might identify outliers in treatment outcomes or variations in healthcare practices.
Identifying trends, patterns, and outliers can provide valuable insights for decision-making and help you develop more effective strategies.
3.3. Improving Decision-Making
Ultimately, the goal of dataset comparison is to improve decision-making. By providing a comprehensive and objective assessment of different datasets, you can make more informed choices about which data to use for your analysis.
For example, if you are building a machine learning model, you might compare different datasets to determine which one provides the best predictive power. Similarly, if you are conducting a scientific study, you might compare different datasets to validate your findings and ensure the robustness of your conclusions.
By making data-driven decisions, you can increase the likelihood of success and achieve better outcomes.
4. Challenges and Limitations of Dataset Comparison
While dataset comparison offers numerous benefits, it also presents several challenges and limitations. Being aware of these challenges is crucial for interpreting the results of your comparison accurately and avoiding potential pitfalls.
4.1. Missing Data and Outliers: Dealing with Imperfections
Missing data and outliers are two common challenges that can affect the accuracy of dataset comparison. Missing data can lead to biased results, while outliers can skew the results and distort the overall picture.
If a dataset contains missing data, it’s essential to impute the missing values before comparing the dataset to another dataset. Imputation is the process of estimating the missing values based on the known values in the dataset. There are several imputation techniques available, including:
- Mean/Median Imputation: Replacing missing values with the mean or median of the available values.
- Regression Imputation: Using a regression model to predict the missing values based on other features in the dataset.
- Multiple Imputation: Creating multiple imputed datasets and combining the results to account for the uncertainty associated with imputation.
Outliers can be identified and removed before comparing datasets. However, it’s crucial to be careful not to remove outliers that are actually valid data points. Outliers can be identified using various methods, including:
- Visual Inspection: Plotting the data and visually identifying data points that are far away from the rest of the data.
- Statistical Methods: Using statistical measures such as the z-score or the interquartile range (IQR) to identify outliers.
- Machine Learning Methods: Using anomaly detection algorithms to identify outliers.
When dealing with missing data and outliers, it’s crucial to document your approach and justify your decisions. This will help ensure the transparency and reproducibility of your analysis.
4.2. Data Privacy and Security Concerns: Protecting Sensitive Information
When comparing datasets, data privacy and security concerns are paramount. This is especially important if the datasets contain sensitive data, such as personal information, financial data, or health records.
One way to mitigate data privacy and security concerns is to use de-identified data. De-identified data has been stripped of any personally identifiable information (PII). This can be done by removing names, addresses, and other PII from the data or by using techniques such as data masking or data anonymization.
Another way to mitigate data privacy and security concerns is to use a secure data-sharing platform. Secure data-sharing platforms allow you to share data with others without compromising the privacy or security of the data. These platforms typically offer features such as:
- Encryption: Protecting data by converting it into an unreadable format.
- Access Controls: Restricting access to data based on user roles and permissions.
- Auditing: Tracking data access and modifications to ensure accountability.
When sharing data, it’s crucial to comply with all applicable privacy regulations, such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA).
4.3. Data Heterogeneity: Bridging the Gaps
Data heterogeneity refers to the differences in data formats, data types, and data quality across different datasets. Data heterogeneity can make it challenging to compare datasets effectively and can lead to inaccurate results.
To address data heterogeneity, it’s essential to perform data standardization and data transformation. Data standardization involves converting data to a common format or scale. Data transformation involves modifying the data to improve its quality or to make it more suitable for analysis.
Here are some common data standardization and transformation techniques:
- Data Type Conversion: Converting data from one data type to another (e.g., converting a string to a number).
- Data Normalization: Scaling numerical data to a common range (e.g., between 0 and 1).
- Data Encoding: Converting categorical data to numerical data (e.g., using one-hot encoding).
- Data Aggregation: Combining data from multiple sources into a single dataset.
By addressing data heterogeneity, you can ensure that your datasets are comparable and that your analysis is based on accurate and consistent data.
5. Best Practices for Effective Dataset Comparison
To maximize the benefits of dataset comparison and minimize the risks, it’s essential to follow best practices. These best practices cover various aspects of the comparison process, from defining your goals to interpreting the results.
5.1. Define Clear Goals: Staying Focused
Before you start comparing datasets, it’s crucial to define clear goals. What do you hope to learn by comparing the datasets? What specific questions are you trying to answer?
Once you know the purpose of the comparison, you can choose the appropriate methods and metrics, and you can focus your efforts on the most relevant aspects of the data.
For example, if you are comparing two datasets of customer satisfaction ratings, your goal might be to identify which dataset provides a more accurate representation of customer sentiment. In this case, you would focus on metrics such as the mean, median, and distribution of the ratings.
5.2. Clean the Data: Ensuring Accuracy
Data cleaning is a crucial step in any data analysis project, and it’s especially important when comparing datasets. Before you compare datasets, you must identify and correct errors in the data, such as missing values, outliers, and duplicate records.
Data cleaning can be a time-consuming process, but it’s essential for ensuring the accuracy of your analysis. The more time you spend cleaning the data, the more confident you can be in the results of your comparison.
5.3. Match the Datasets: Creating a Level Playing Field
When comparing datasets, it’s essential to match them on key features, such as the period covered, the population represented, and the data collection methods. This will make the comparison more meaningful and reduce the risk of spurious findings.
For example, if you are comparing sales data from two different years, you should ensure that the data covers the same period and that the sales data is collected using the same methods. Similarly, if you are comparing patient data from two different hospitals, you should ensure that the patients are similar in terms of age, gender, and medical history.
5.4. Interpret the Results Carefully: Avoiding Misinterpretations
Once you have compared the datasets, it’s crucial to interpret the results carefully. Be aware of the potential for bias, and use a structured data governance framework to maintain data quality.
It’s also essential to consider the limitations of your analysis. What are the potential sources of error? How might these errors affect your conclusions?
By interpreting the results carefully and acknowledging the limitations of your analysis, you can avoid misinterpretations and make more informed decisions.
5.5. Document Your Process: Ensuring Transparency
Throughout the dataset comparison process, it’s essential to document your steps and decisions. This will help ensure the transparency and reproducibility of your analysis.
Your documentation should include:
- The goals of the comparison
- The methods and metrics used
- The data cleaning steps performed
- The assumptions made
- The limitations of the analysis
- The results of the comparison
By documenting your process, you can make it easier for others to understand your analysis and to reproduce your results.
6. Real-World Applications of Dataset Comparison
Dataset comparison is a valuable technique in a wide range of industries and applications. Here are a few examples:
- Healthcare: Comparing patient data from different hospitals to identify variations in treatment outcomes and healthcare practices.
- Finance: Comparing financial data from different companies to identify investment opportunities and assess risk.
- Marketing: Comparing customer data from different sources to identify customer segments and personalize marketing campaigns.
- Manufacturing: Comparing production data from different factories to identify inefficiencies and improve productivity.
- Environmental Science: Comparing environmental data from different locations to monitor pollution levels and assess the impact of climate change.
In each of these applications, dataset comparison can provide valuable insights and help organizations make more informed decisions.
7. Tools and Technologies for Dataset Comparison
Several tools and technologies can assist you in comparing datasets. The choice of tool depends on your specific needs and technical expertise.
- Statistical Software Packages: SPSS, SAS, R, and Stata are powerful statistical software packages that offer a wide range of statistical tests and data visualization tools.
- Data Visualization Tools: Tableau, Power BI, and QlikView are popular data visualization tools that allow you to create interactive dashboards and reports.
- Programming Languages: Python and R are versatile programming languages with extensive libraries for data analysis and visualization.
- Cloud-Based Data Platforms: Google Cloud, Amazon Web Services (AWS), and Microsoft Azure offer cloud-based data platforms with a variety of data analysis and machine learning services.
COMPARE.EDU.VN offers resources and tutorials on using various tools and technologies for dataset comparison, helping you choose the right tools for your needs.
8. Future Trends in Dataset Comparison
The field of dataset comparison is constantly evolving, with new techniques and technologies emerging all the time. Here are some future trends to watch out for:
- Automated Dataset Comparison: The development of automated tools that can automatically compare datasets and identify potential issues.
- AI-Powered Dataset Comparison: The use of artificial intelligence (AI) and machine learning (ML) to enhance dataset comparison techniques and to identify subtle differences between datasets.
- Real-Time Dataset Comparison: The ability to compare datasets in real-time, allowing for more timely and informed decision-making.
- Data Governance and Data Quality: The increasing importance of data governance and data quality in ensuring the accuracy and reliability of dataset comparison.
Staying up-to-date with these trends will help you leverage the latest advancements in dataset comparison and improve the quality of your data-driven decisions.
9. Conclusion
Dataset comparison is a critical process for ensuring data quality, identifying trends and patterns, and improving decision-making. By following best practices and using the right tools and technologies, you can effectively compare datasets and gain valuable insights.
Remember, the key to successful dataset comparison is to define clear goals, clean the data thoroughly, match the datasets on key features, and interpret the results carefully.
Visit COMPARE.EDU.VN at 333 Comparison Plaza, Choice City, CA 90210, United States, or contact us via WhatsApp at +1 (626) 555-9090 for comprehensive resources and expert guidance on dataset comparison. Let us help you make data-driven decisions with confidence.
Navigating the complexities of dataset comparison can be daunting, but COMPARE.EDU.VN is here to simplify the process. Explore our comprehensive guides, compare various techniques, and choose the best approach for your specific needs. Let us empower you to make informed decisions with confidence.
10. Frequently Asked Questions (FAQ)
Q1: What is the primary goal of dataset comparison?
The primary goal is to ensure data quality, identify trends, and improve decision-making by comparing and contrasting different datasets.
Q2: What are some common challenges in dataset comparison?
Common challenges include missing data, outliers, data privacy concerns, and data heterogeneity.
Q3: How can I address missing data in dataset comparison?
You can use imputation techniques such as mean/median imputation, regression imputation, or multiple imputation to estimate missing values.
Q4: What are the benefits of using data visualization in dataset comparison?
Data visualization helps in identifying patterns, anomalies, and trends that might be missed by statistical analysis alone.
Q5: Why is data cleaning important before comparing datasets?
Data cleaning ensures accuracy by correcting errors like missing values, outliers, and duplicate records, leading to more reliable analysis.
Q6: How can I ensure data privacy when comparing sensitive datasets?
Use de-identified data and secure data-sharing platforms to protect personally identifiable information and comply with privacy regulations.
Q7: What is exploratory data analysis (EDA) and why is it useful for dataset comparison?
EDA is a comprehensive approach involving data cleaning, visualization, and statistical analysis to understand data characteristics and identify potential issues.
Q8: What tools can I use for dataset comparison?
Tools include statistical software packages (SPSS, SAS, R), data visualization tools (Tableau, Power BI), and programming languages (Python, R).
Q9: What are some future trends in dataset comparison?
Future trends include automated dataset comparison, AI-powered dataset comparison, real-time dataset comparison, and a greater emphasis on data governance and quality.
Q10: Where can I find more resources and expert guidance on dataset comparison?
Visit COMPARE.EDU.VN at 333 Comparison Plaza, Choice City, CA 90210, United States, or contact us via WhatsApp at +1 (626) 555-9090 for comprehensive resources and expert guidance.
Remember, effective dataset comparison requires careful planning, execution, and interpretation. By following the guidelines outlined in this article and leveraging the resources available at compare.edu.vn, you can unlock the full potential of your data and make more informed decisions. Start your data comparison journey today and transform your data into actionable insights.