Comparing two values of the same column in SQL involves leveraging SQL’s capabilities to perform comparisons within a single table. At COMPARE.EDU.VN, we aim to clarify this process, ensuring you can effectively analyze data, identify patterns, and derive meaningful insights. SQL offers various methods for performing these comparisons, each suited for different scenarios and analytical goals. Comparing values within a column can be achieved through self-joins, window functions, or subqueries, offering flexibility in your approach. Explore data analysis techniques, self-referential relationships, and conditional querying.
1. Understanding the Need for Comparing Values in the Same Column
Why would you want to compare values within the same column of an SQL table? Understanding the motivation behind this task is essential for framing the right SQL queries. Here are a few key reasons:
- Identifying Trends: Comparing current values against past values (e.g., sales figures month-over-month) can reveal trends and patterns.
- Detecting Outliers: Spotting unusual deviations from the norm can highlight anomalies requiring further investigation.
- Calculating Differences: Determining the difference between related values (e.g., the price change of a product over time) provides quantitative insights.
- Ranking: Determining the rank of values within a column, such as identifying the top-performing products or employees.
- Self-Referential Relationships: Exploring hierarchical data structures, such as employee-manager relationships within a company.
2. Techniques for Comparing Values in the Same Column
SQL provides several powerful techniques to compare values within the same column. The most suitable approach depends on the specific comparison you want to make and the structure of your data. Let’s explore some of these methods:
2.1 Self-Joins
A self-join involves joining a table to itself. This technique allows you to compare values in different rows of the same table as if they were columns in separate tables.
When to Use Self-Joins:
- When you need to compare values across different rows based on a related attribute.
- When identifying pairs of rows that satisfy a specific condition.
- When working with self-referential relationships, such as hierarchical data.
How Self-Joins Work:
- Alias the Table: Assign different aliases to the same table in the
FROMclause (e.g.,table AS t1,table AS t2). - Join on a Related Column: Use the
JOINclause (typicallyINNER JOINorLEFT JOIN) to connect the table aliases based on a common column that establishes the relationship between the rows you want to compare. - Specify Comparison Conditions: In the
WHEREclause, add conditions that compare the values in the target column from the different table aliases.
Example of Self-Join:
Let’s say you have a table named “Employees” with columns EmployeeID, EmployeeName, and ManagerID. To find all employees who report to the same manager, you can use a self-join:
SELECT
e1.EmployeeName AS Employee1,
e2.EmployeeName AS Employee2,
m.EmployeeName AS Manager
FROM
Employees AS e1
INNER JOIN
Employees AS e2 ON e1.ManagerID = e2.ManagerID AND e1.EmployeeID <> e2.EmployeeID
INNER JOIN
Employees AS m ON e1.ManagerID = m.EmployeeID;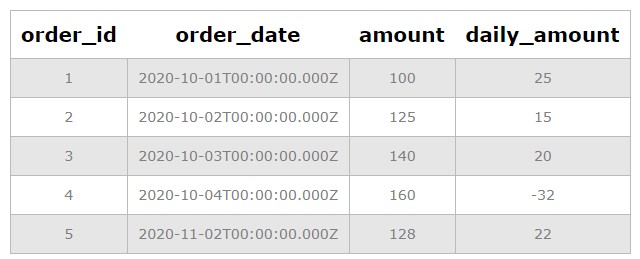 Employees Table Self Join
Employees Table Self Join
Explanation:
- This query joins the
Employeestable to itself twice, aliased ase1,e2, andm. - The first
INNER JOINconnectse1ande2based on the condition that theirManagerIDvalues are equal, ensuring that both employees report to the same manager. The additional conditione1.EmployeeID <> e2.EmployeeIDprevents comparing an employee to themselves. - The second
INNER JOINconnectse1tom(representing the manager) based on the condition thate1.ManagerIDmatchesm.EmployeeID, allowing us to retrieve the manager’s name. - The
SELECTclause retrieves the names of the two employees and their manager.
2.2 Window Functions
Window functions perform calculations across a set of table rows that are related to the current row. They allow you to access data from other rows without the need for self-joins.
When to Use Window Functions:
- When you need to perform calculations involving neighboring rows (e.g., calculating moving averages, running totals).
- When you need to rank values within a column.
- When you need to access the previous or next row’s value in a sorted dataset.
How Window Functions Work:
OVER()Clause: TheOVER()clause defines the “window” of rows over which the function operates.PARTITION BY(Optional): ThePARTITION BYclause divides the rows into partitions, and the window function is applied to each partition independently.ORDER BY(Optional): TheORDER BYclause specifies the order of rows within each partition. This is essential for functions that rely on the order of rows, such asLAG(),LEAD(), andROW_NUMBER().- Window Function: The window function itself performs the calculation. Common window functions include:
LAG(column, offset, default): Accesses the value of a column from a previous row.LEAD(column, offset, default): Accesses the value of a column from a subsequent row.ROW_NUMBER(): Assigns a unique sequential integer to each row within the partition.RANK(): Assigns a rank to each row within the partition based on the specified order.DENSE_RANK(): Similar toRANK(), but assigns consecutive ranks without gaps.SUM(),AVG(),MIN(),MAX(): Aggregate functions that calculate the sum, average, minimum, or maximum of a column within the window.
Example of Window Function:
Let’s say you have a table named “Sales” with columns SaleDate and Amount. To calculate the month-over-month change in sales, you can use the LAG() window function:
SELECT
SaleDate,
Amount,
Amount - LAG(Amount, 1, 0) OVER (ORDER BY SaleDate) AS MonthOverMonthChange
FROM
Sales;Explanation:
- The
LAG(Amount, 1, 0)function retrieves theAmountfrom the previous row (offset 1) based on theSaleDateorder. If there is no previous row (for the first row), it defaults to 0. - The
OVER (ORDER BY SaleDate)clause specifies that the window function should be applied to the entire table, ordered bySaleDate. - The query calculates the difference between the current
Amountand the previous month’sAmount, providing the month-over-month change in sales.
2.3 Subqueries
Subqueries are queries nested within another query. They can be used to compare values against the results of another query performed on the same table.
When to Use Subqueries:
- When you need to compare values against an aggregate value calculated from the same table (e.g., finding all customers whose orders are above the average order value).
- When you need to filter rows based on a condition that involves a calculation on the same table.
- When you need to correlate data across different rows based on a complex condition.
How Subqueries Work:
- Inner Query: The subquery (inner query) is enclosed in parentheses and executed first.
- Outer Query: The outer query uses the result of the subquery in its
WHERE,HAVING, orSELECTclause. - Types of Subqueries:
- Scalar Subquery: Returns a single value.
- Column Subquery: Returns a single column of multiple rows.
- Table Subquery: Returns a complete table (multiple columns and rows).
Example of Subquery:
Let’s say you have a table named “Orders” with columns OrderID, CustomerID, and OrderValue. To find all orders with an OrderValue greater than the average order value, you can use a subquery:
SELECT
OrderID,
CustomerID,
OrderValue
FROM
Orders
WHERE
OrderValue > (SELECT AVG(OrderValue) FROM Orders);Explanation:
- The subquery
(SELECT AVG(OrderValue) FROM Orders)calculates the averageOrderValuefrom the entireOrderstable. - The outer query selects the
OrderID,CustomerID, andOrderValuefrom theOrderstable where theOrderValueis greater than the average calculated by the subquery.
3. Practical Examples of Comparing Values in the Same Column
To illustrate these techniques, let’s consider a table named “Products” with the following columns:
ProductID(INT, Primary Key)ProductName(VARCHAR)Category(VARCHAR)Price(DECIMAL)UnitsInStock(INT)
3.1 Example: Finding Products with Price Higher Than Average Price in Their Category
This example demonstrates how to combine self-joins and subqueries to perform a more complex comparison.
SELECT
p.ProductName,
p.Category,
p.Price
FROM
Products AS p
INNER JOIN
(SELECT
Category,
AVG(Price) AS AvgPrice
FROM
Products
GROUP BY
Category) AS category_avg
ON
p.Category = category_avg.Category
WHERE
p.Price > category_avg.AvgPrice;Explanation:
- The subquery calculates the average price for each category.
- The outer query joins the
Productstable with the result of the subquery on theCategorycolumn. - The
WHEREclause filters the results to include only products whose price is higher than the average price in their category.
3.2 Example: Calculating the Difference in UnitsInStock Between Consecutive Products in the Same Category
This example demonstrates how to use window functions to compare values in adjacent rows.
SELECT
ProductID,
ProductName,
Category,
UnitsInStock,
UnitsInStock - LAG(UnitsInStock, 1, 0) OVER (PARTITION BY Category ORDER BY ProductID) AS UnitsInStockChange
FROM
Products;Explanation:
- The
LAG(UnitsInStock, 1, 0)function retrieves theUnitsInStockfrom the previous row within the same category, ordered byProductID. If there is no previous row, it defaults to 0. - The
OVER (PARTITION BY Category ORDER BY ProductID)clause specifies that the window function should be applied within each category, ordered byProductID. - The query calculates the difference between the current
UnitsInStockand the previous product’sUnitsInStockin the same category.
3.3 Example: Identifying Products That Have a Lower Price Than the Product With the Highest UnitsInStock
This example showcases the use of subqueries to compare individual values against a specific value derived from the same table.
SELECT
ProductName,
Price,
UnitsInStock
FROM
Products
WHERE
Price < (SELECT MIN(Price) FROM Products WHERE UnitsInStock = (SELECT MAX(UnitsInStock) FROM Products));Explanation:
- The innermost subquery
(SELECT MAX(UnitsInStock) FROM Products)finds the highest value ofUnitsInStockin the entireProductstable. - The next subquery
(SELECT MIN(Price) FROM Products WHERE UnitsInStock = (SELECT MAX(UnitsInStock) FROM Products))finds the lowest price among the products with the highest number of units in stock. - The outer query selects the
ProductName,Price, andUnitsInStockfrom theProductstable where thePriceis lower than the lowest price among the products with the highestUnitsInStock.
4. Advanced Considerations
While the techniques described above cover most common scenarios, here are a few advanced considerations when comparing values in the same column:
- Handling NULL Values: When comparing values, be mindful of
NULLvalues.NULLvalues represent missing or unknown data, and comparisons involvingNULLoften result inNULL. Use theIS NULLandIS NOT NULLoperators to handleNULLvalues explicitly. - Performance Optimization: Comparing values within the same column can be resource-intensive, especially for large tables. Consider using indexes on the columns involved in the comparison to improve query performance.
- Data Types: Ensure that the data types of the columns being compared are compatible. If they are not, you may need to use type conversion functions (e.g.,
CAST(),CONVERT()) to ensure accurate comparisons. - Complex Comparisons: For highly complex comparisons, consider using Common Table Expressions (CTEs) to break down the query into smaller, more manageable steps. CTEs allow you to define temporary named result sets that can be referenced within the main query.
5. Conclusion: Empowering Data-Driven Decisions
Comparing values within the same column in SQL is a fundamental skill for data analysis and decision-making. By mastering techniques like self-joins, window functions, and subqueries, you can unlock valuable insights from your data and gain a deeper understanding of the relationships and patterns within your datasets.
At COMPARE.EDU.VN, we understand the challenges of navigating complex data analysis tasks. That’s why we provide comprehensive guides and resources to empower you with the knowledge and skills you need to succeed. Whether you’re a student, a business professional, or a data enthusiast, our platform offers a wealth of information to help you make informed decisions and drive positive outcomes.
Ready to take your data analysis skills to the next level? Visit COMPARE.EDU.VN today and explore our extensive library of tutorials, case studies, and expert insights. Let us help you unlock the power of data and make smarter, more data-driven decisions.
6. Frequently Asked Questions (FAQ)
Q1: What is a self-join in SQL?
A: A self-join is a type of join operation where a table is joined with itself. It’s useful for comparing rows within the same table, treating them as if they were in separate tables. This is achieved by using table aliases to distinguish between the different instances of the same table in the query.
Q2: How do window functions help in comparing values in the same column?
A: Window functions perform calculations across a set of table rows that are related to the current row. They allow you to access data from other rows without the need for self-joins. For example, you can use the LAG() function to access the value of a previous row or the LEAD() function to access the value of a subsequent row, enabling comparisons between consecutive values.
Q3: What are subqueries, and how can they be used for comparing values in the same column?
A: Subqueries are queries nested within another query. They can be used to compare values against the results of another query performed on the same table. For example, you can use a subquery to calculate the average value of a column and then compare individual values in that column against the calculated average.
Q4: How do I handle NULL values when comparing values in the same column?
A: When comparing values, be mindful of NULL values. NULL values represent missing or unknown data, and comparisons involving NULL often result in NULL. Use the IS NULL and IS NOT NULL operators to handle NULL values explicitly. For example, you can use WHERE column IS NULL to select rows where the column value is NULL.
Q5: Can you provide an example of using a self-join to find duplicate values in a column?
A: Yes, you can use a self-join to find duplicate values in a column. Here’s an example:
SELECT
t1.ColumnName
FROM
TableName AS t1
INNER JOIN
TableName AS t2 ON t1.ColumnName = t2.ColumnName AND t1.PrimaryKeyColumn <> t2.PrimaryKeyColumn
GROUP BY
t1.ColumnName
HAVING
COUNT(*) > 1;Q6: How can I improve the performance of queries that compare values in the same column?
A: Comparing values within the same column can be resource-intensive, especially for large tables. Consider using indexes on the columns involved in the comparison to improve query performance. Also, try to simplify the query logic and avoid using complex subqueries or window functions unnecessarily.
Q7: What is the difference between RANK() and DENSE_RANK() window functions?
A: Both RANK() and DENSE_RANK() are window functions that assign a rank to each row within a partition based on the specified order. The main difference is how they handle ties (rows with the same value). RANK() assigns the same rank to tied rows and then skips the subsequent rank(s), resulting in gaps in the ranking sequence. DENSE_RANK(), on the other hand, assigns the same rank to tied rows but does not skip any ranks, resulting in a consecutive ranking sequence.
Q8: Can I use multiple window functions in the same query?
A: Yes, you can use multiple window functions in the same query. Each window function can have its own OVER() clause, allowing you to define different windows and ordering for each function. This can be useful for performing multiple calculations involving different sets of related rows.
Q9: How can I use Common Table Expressions (CTEs) to simplify complex comparisons?
A: CTEs allow you to define temporary named result sets that can be referenced within the main query. You can use CTEs to break down the query into smaller, more manageable steps, making it easier to understand and maintain. For example, you can use a CTE to calculate an intermediate result set and then use that result set in the main query to perform the final comparison.
Q10: Are there any limitations to using self-joins?
A: Yes, self-joins can be resource-intensive, especially for large tables. The query optimizer may struggle to efficiently process self-joins, resulting in poor performance. Also, self-joins can make the query logic more complex and harder to understand. Consider using alternative techniques like window functions or subqueries if they can achieve the same result with better performance and readability.
Still have questions? Contact us at:
Address: 333 Comparison Plaza, Choice City, CA 90210, United States
Whatsapp: +1 (626) 555-9090
Website: COMPARE.EDU.VN
Let compare.edu.vn guide you to the best choice.
