Comparing two SQL tables is a common task in database management, data warehousing, and data migration. Whether you’re identifying discrepancies, validating data integrity, or synchronizing databases, understanding How To Compare Two Sql Tables efficiently is crucial. COMPARE.EDU.VN provides expert comparisons to help you make informed decisions. This guide explores various methods and techniques, ensuring you can choose the best approach for your specific needs.
1. Understanding the Need for SQL Table Comparison
1.1. Why Compare SQL Tables?
Comparing SQL tables is essential for several reasons:
- Data Validation: Ensuring data consistency between source and destination tables, especially after data migration or ETL (Extract, Transform, Load) processes.
- Identifying Discrepancies: Pinpointing differences in data values, missing records, or unexpected entries.
- Data Synchronization: Synchronizing data between two tables to keep them aligned, useful in replication scenarios.
- Auditing: Tracking changes over time to understand how data has evolved.
- Testing: Validating the results of data transformations or calculations.
1.2. Scenarios Where Table Comparison is Useful
Consider these practical scenarios:
- Data Migration: After migrating a database to a new server or schema, you need to verify that all data was transferred correctly.
- ETL Processes: During ETL, data is extracted, transformed, and loaded into a data warehouse. Comparing source and target tables ensures data integrity.
- Backup Verification: Comparing a backup table with the original table to ensure the backup is complete and accurate.
- Replication: Ensuring that replicated tables in different databases are synchronized.
- Data Quality Monitoring: Regularly comparing tables to detect data quality issues, such as inconsistencies or errors.
2. Key Concepts and Terminology
2.1. SQL (Structured Query Language)
SQL is a standard language for managing and manipulating relational databases. Understanding SQL is fundamental for comparing tables.
2.2. Relational Database Management System (RDBMS)
An RDBMS is a software system used to maintain relational databases. Examples include MySQL, PostgreSQL, SQL Server, and Oracle.
2.3. Primary Key
A primary key is a unique identifier for each record in a table. It ensures that each row can be uniquely identified and is used for relationships between tables.
2.4. Foreign Key
A foreign key is a field in one table that refers to the primary key in another table. It establishes a link between the two tables.
2.5. JOIN Operations
JOIN operations combine rows from two or more tables based on a related column. Common types include INNER JOIN, LEFT JOIN, RIGHT JOIN, and FULL OUTER JOIN.
2.6. EXCEPT Operator
The EXCEPT operator returns rows from the first query that are not present in the second query. It’s useful for identifying differences between two result sets.
2.7. INTERSECT Operator
The INTERSECT operator returns rows that are common to both queries. It helps identify matching records between two tables.
3. Methods for Comparing Two SQL Tables
3.1. Using the EXCEPT Operator
3.1.1. Basic Syntax
The EXCEPT operator is a straightforward way to find differences between two tables.
SELECT column1, column2, ...
FROM TableA
EXCEPT
SELECT column1, column2, ...
FROM TableB;This query returns all rows from TableA that are not present in TableB.
3.1.2. Example: Identifying Differences
Consider two tables: Employees_Source and Employees_Destination.
-- Create the Employees_Source table
CREATE TABLE Employees_Source (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100)
);
-- Insert sample data into Employees_Source
INSERT INTO Employees_Source (EmployeeID, FirstName, LastName, Email) VALUES
(1, 'John', 'Doe', '[email protected]'),
(2, 'Jane', 'Smith', '[email protected]'),
(3, 'Alice', 'Johnson', '[email protected]');
-- Create the Employees_Destination table
CREATE TABLE Employees_Destination (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100)
);
-- Insert sample data into Employees_Destination
INSERT INTO Employees_Destination (EmployeeID, FirstName, LastName, Email) VALUES
(1, 'John', 'Doe', '[email protected]'),
(2, 'Jane', 'Smith', '[email protected]'),
(4, 'Bob', 'Williams', '[email protected]');To find employees in Employees_Source but not in Employees_Destination:
SELECT EmployeeID, FirstName, LastName, Email
FROM Employees_Source
EXCEPT
SELECT EmployeeID, FirstName, LastName, Email
FROM Employees_Destination;This query returns:
EmployeeID | FirstName | LastName | Email
-----------|-----------|----------|----------------------
3 | Alice | Johnson | [email protected]3.1.3. Considerations
- Column Matching: The number and data types of columns in both SELECT statements must match.
- Performance: For large tables, EXCEPT can be slower than other methods like JOIN.
- Null Values: EXCEPT treats NULL values as equal for comparison purposes.
3.2. Using JOIN Operations
3.2.1. LEFT JOIN for Identifying Missing Records
A LEFT JOIN returns all rows from the left table and the matching rows from the right table. You can use it to find records that exist in one table but not the other.
SELECT A.column1, A.column2, ...
FROM TableA A
LEFT JOIN TableB B ON A.column1 = B.column1 AND A.column2 = B.column2 AND ...
WHERE B.column1 IS NULL;This query returns all rows from TableA where there is no matching row in TableB.
3.2.2. Example: Finding Missing Employees
Using the Employees_Source and Employees_Destination tables:
SELECT
es.EmployeeID,
es.FirstName,
es.LastName,
es.Email
FROM
Employees_Source es
LEFT JOIN
Employees_Destination ed ON es.EmployeeID = ed.EmployeeID
WHERE
ed.EmployeeID IS NULL;This query returns:
EmployeeID | FirstName | LastName | Email
-----------|-----------|----------|----------------------
3 | Alice | Johnson | [email protected]3.2.3. FULL OUTER JOIN for Comprehensive Comparison
A FULL OUTER JOIN returns all rows when there is a match in either the left or right table. It’s useful for identifying all differences and similarities.
SELECT
COALESCE(A.column1, B.column1) AS column1,
COALESCE(A.column2, B.column2) AS column2,
...
FROM
TableA A
FULL OUTER JOIN
TableB B ON A.column1 = B.column1 AND A.column2 = B.column2 AND ...
WHERE
A.column1 IS NULL OR B.column1 IS NULL OR A.column2 <> B.column2 OR ...;This query returns all rows that are different between TableA and TableB.
3.2.4. Example: Comprehensive Employee Comparison
SELECT
COALESCE(es.EmployeeID, ed.EmployeeID) AS EmployeeID,
es.FirstName AS SourceFirstName,
ed.FirstName AS DestinationFirstName,
es.LastName AS SourceLastName,
ed.LastName AS DestinationLastName,
es.Email AS SourceEmail,
ed.Email AS DestinationEmail
FROM
Employees_Source es
FULL OUTER JOIN
Employees_Destination ed ON es.EmployeeID = ed.EmployeeID
WHERE
es.EmployeeID IS NULL OR ed.EmployeeID IS NULL OR
es.FirstName <> ed.FirstName OR es.LastName <> ed.LastName OR
es.Email <> ed.Email;This query returns:
EmployeeID | SourceFirstName | DestinationFirstName | SourceLastName | DestinationLastName | SourceEmail | DestinationEmail
-----------|-----------------|----------------------|----------------|---------------------|--------------------------|--------------------------
3 | Alice | NULL | Johnson | NULL | [email protected] | NULL
4 | NULL | Bob | NULL | Williams | NULL | [email protected]3.2.5. Considerations
- Performance: JOIN operations can be optimized with proper indexing.
- Complexity: FULL OUTER JOIN queries can be complex and require careful consideration of the join conditions and WHERE clauses.
- Null Handling: Use
COALESCEto handle NULL values effectively.
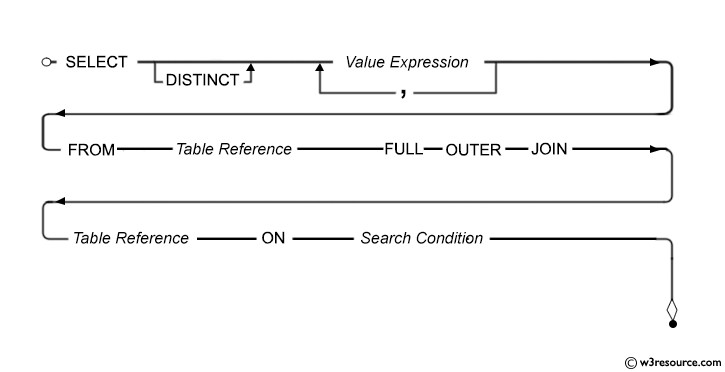 SQL FULL OUTER JOIN
SQL FULL OUTER JOIN
3.3. Using the INTERSECT Operator
3.3.1. Basic Syntax
The INTERSECT operator returns rows that are common to both tables.
SELECT column1, column2, ...
FROM TableA
INTERSECT
SELECT column1, column2, ...
FROM TableB;This query returns all rows that exist in both TableA and TableB.
3.3.2. Example: Finding Common Employees
SELECT EmployeeID, FirstName, LastName, Email
FROM Employees_Source
INTERSECT
SELECT EmployeeID, FirstName, LastName, Email
FROM Employees_Destination;This query returns:
EmployeeID | FirstName | LastName | Email
-----------|-----------|----------|----------------------
1 | John | Doe | [email protected]
2 | Jane | Smith | [email protected]3.3.3. Considerations
- Column Matching: Similar to EXCEPT, the number and data types of columns must match.
- Performance: INTERSECT can be slower than JOIN for large tables.
- Null Values: INTERSECT treats NULL values as equal.
3.4. Using Hashing Techniques
3.4.1. Generating Hash Values
Hashing involves generating a unique hash value for each row based on its column values. Comparing hash values can quickly identify differences.
-- Example in SQL Server
SELECT
*,
HASHBYTES('SHA2_256', CONCAT(column1, column2, column3, ...)) AS RowHash
FROM
TableA;3.4.2. Comparing Hash Values
Compare the hash values between two tables to identify differing rows.
SELECT
A.*,
B.*
FROM
(SELECT *, HASHBYTES('SHA2_256', CONCAT(column1, column2, column3, ...)) AS RowHash FROM TableA) A
FULL OUTER JOIN
(SELECT *, HASHBYTES('SHA2_256', CONCAT(column1, column2, column3, ...)) AS RowHash FROM TableB) B
ON
A.column1 = B.column1 AND A.RowHash = B.RowHash
WHERE
A.RowHash IS NULL OR B.RowHash IS NULL;3.4.3. Example: Hashing Employee Records
SELECT
es.*,
HASHBYTES('SHA2_256', CONCAT(es.EmployeeID, es.FirstName, es.LastName, es.Email)) AS RowHash
FROM
Employees_Source es;
SELECT
ed.*,
HASHBYTES('SHA2_256', CONCAT(ed.EmployeeID, ed.FirstName, ed.LastName, ed.Email)) AS RowHash
FROM
Employees_Destination ed;Compare the hash values:
SELECT
COALESCE(es.EmployeeID, ed.EmployeeID) AS EmployeeID,
es.FirstName AS SourceFirstName,
ed.FirstName AS DestinationFirstName,
es.LastName AS SourceLastName,
ed.LastName AS DestinationLastName,
es.Email AS SourceEmail,
ed.Email AS DestinationEmail
FROM
(SELECT *, HASHBYTES('SHA2_256', CONCAT(EmployeeID, FirstName, LastName, Email)) AS RowHash FROM Employees_Source) es
FULL OUTER JOIN
(SELECT *, HASHBYTES('SHA2_256', CONCAT(EmployeeID, FirstName, LastName, Email)) AS RowHash FROM Employees_Destination) ed
ON
es.EmployeeID = ed.EmployeeID AND es.RowHash = ed.RowHash
WHERE
es.RowHash IS NULL OR ed.RowHash IS NULL;3.4.4. Considerations
- Hash Collisions: While rare, hash collisions can occur, leading to false positives.
- Complexity: Implementing hashing requires understanding of hash functions and their properties.
- Performance: Hashing can be faster than comparing individual columns for large tables.
3.5. Using CHECKSUM Function
3.5.1. Generating Checksums
The CHECKSUM function calculates a checksum value for a row. Comparing checksums is a simpler alternative to hashing.
SELECT
*,
CHECKSUM(column1, column2, column3, ...) AS RowChecksum
FROM
TableA;3.5.2. Comparing Checksums
Compare the checksum values between two tables to identify differing rows.
SELECT
A.*,
B.*
FROM
(SELECT *, CHECKSUM(column1, column2, column3, ...) AS RowChecksum FROM TableA) A
FULL OUTER JOIN
(SELECT *, CHECKSUM(column1, column2, column3, ...) AS RowChecksum FROM TableB) B
ON
A.column1 = B.column1 AND A.RowChecksum = B.RowChecksum
WHERE
A.RowChecksum IS NULL OR B.RowChecksum IS NULL;3.5.3. Example: Checksum for Employee Records
SELECT
es.*,
CHECKSUM(es.EmployeeID, es.FirstName, es.LastName, es.Email) AS RowChecksum
FROM
Employees_Source es;
SELECT
ed.*,
CHECKSUM(ed.EmployeeID, ed.FirstName, ed.LastName, ed.Email) AS RowChecksum
FROM
Employees_Destination ed;Compare the checksum values:
SELECT
COALESCE(es.EmployeeID, ed.EmployeeID) AS EmployeeID,
es.FirstName AS SourceFirstName,
ed.FirstName AS DestinationFirstName,
es.LastName AS SourceLastName,
ed.LastName AS DestinationLastName,
es.Email AS SourceEmail,
ed.Email AS DestinationEmail
FROM
(SELECT *, CHECKSUM(EmployeeID, FirstName, LastName, Email) AS RowChecksum FROM Employees_Source) es
FULL OUTER JOIN
(SELECT *, CHECKSUM(EmployeeID, FirstName, LastName, Email) AS RowChecksum FROM Employees_Destination) ed
ON
es.EmployeeID = ed.EmployeeID AND es.RowChecksum = ed.RowChecksum
WHERE
es.RowChecksum IS NULL OR ed.RowChecksum IS NULL;3.5.4. Considerations
- Checksum Collisions: Checksum collisions are more likely than hash collisions.
- Simplicity: CHECKSUM is easier to implement than hashing.
- Performance: CHECKSUM can be faster than comparing individual columns, but less reliable than hashing.
3.6. Using Window Functions
3.6.1. Partitioning and Ordering
Window functions can partition and order data within a result set, making it easier to compare rows based on specific criteria.
SELECT
column1,
column2,
...,
ROW_NUMBER() OVER (PARTITION BY column1 ORDER BY column2) AS RowNum
FROM
TableA;3.6.2. Comparing Rows
Use window functions to compare rows within a table or between two tables.
WITH
SourceData AS (
SELECT
column1,
column2,
...,
ROW_NUMBER() OVER (PARTITION BY column1 ORDER BY column2) AS RowNum
FROM
TableA
),
DestinationData AS (
SELECT
column1,
column2,
...,
ROW_NUMBER() OVER (PARTITION BY column1 ORDER BY column2) AS RowNum
FROM
TableB
)
SELECT
sd.*,
dd.*
FROM
SourceData sd
FULL OUTER JOIN
DestinationData dd ON sd.column1 = dd.column1 AND sd.RowNum = dd.RowNum
WHERE
sd.column1 IS NULL OR dd.column1 IS NULL OR sd.column2 <> dd.column2 OR ...;3.6.3. Example: Window Functions for Employee Comparison
WITH
SourceData AS (
SELECT
EmployeeID,
FirstName,
LastName,
Email,
ROW_NUMBER() OVER (PARTITION BY EmployeeID ORDER BY FirstName) AS RowNum
FROM
Employees_Source
),
DestinationData AS (
SELECT
EmployeeID,
FirstName,
LastName,
Email,
ROW_NUMBER() OVER (PARTITION BY EmployeeID ORDER BY FirstName) AS RowNum
FROM
Employees_Destination
)
SELECT
COALESCE(sd.EmployeeID, dd.EmployeeID) AS EmployeeID,
sd.FirstName AS SourceFirstName,
dd.FirstName AS DestinationFirstName,
sd.LastName AS SourceLastName,
dd.LastName AS DestinationLastName,
sd.Email AS SourceEmail,
dd.Email AS DestinationEmail
FROM
SourceData sd
FULL OUTER JOIN
DestinationData dd ON sd.EmployeeID = dd.EmployeeID AND sd.RowNum = dd.RowNum
WHERE
sd.EmployeeID IS NULL OR dd.EmployeeID IS NULL OR
sd.FirstName <> dd.FirstName OR sd.LastName <> dd.LastName OR
sd.Email <> dd.Email;3.6.4. Considerations
- Complexity: Window functions can be complex and require a good understanding of SQL.
- Performance: Window functions can be resource-intensive for large tables.
- Flexibility: Window functions offer great flexibility for comparing rows based on various criteria.
3.7. Using Custom Scripts and Procedures
3.7.1. Creating Custom Scripts
For complex comparisons, you can create custom scripts or stored procedures to handle specific requirements.
-- Example of a custom script in SQL Server
CREATE PROCEDURE CompareTables
@SourceTable VARCHAR(255),
@DestinationTable VARCHAR(255)
AS
BEGIN
-- Your custom comparison logic here
END;3.7.2. Implementing Comparison Logic
Implement custom comparison logic within the script, such as looping through rows and comparing individual column values.
CREATE PROCEDURE CompareTables
@SourceTable VARCHAR(255),
@DestinationTable VARCHAR(255)
AS
BEGIN
DECLARE @SQL VARCHAR(MAX);
SET @SQL = '
SELECT
COALESCE(s.EmployeeID, d.EmployeeID) AS EmployeeID,
s.FirstName AS SourceFirstName,
d.FirstName AS DestinationFirstName,
s.LastName AS SourceLastName,
d.LastName AS DestinationLastName,
s.Email AS SourceEmail,
d.Email AS DestinationEmail
FROM
' + @SourceTable + ' s
FULL OUTER JOIN
' + @DestinationTable + ' d ON s.EmployeeID = d.EmployeeID
WHERE
s.EmployeeID IS NULL OR d.EmployeeID IS NULL OR
s.FirstName <> d.FirstName OR s.LastName <> d.LastName OR
s.Email <> d.Email;';
EXEC(@SQL);
END;3.7.3. Example: Custom Procedure for Employee Comparison
CREATE PROCEDURE CompareEmployeeTables
@SourceTable VARCHAR(255),
@DestinationTable VARCHAR(255)
AS
BEGIN
DECLARE @SQL VARCHAR(MAX);
SET @SQL = '
SELECT
COALESCE(s.EmployeeID, d.EmployeeID) AS EmployeeID,
s.FirstName AS SourceFirstName,
d.FirstName AS DestinationFirstName,
s.LastName AS SourceLastName,
d.LastName AS DestinationLastName,
s.Email AS SourceEmail,
d.Email AS DestinationEmail
FROM
' + @SourceTable + ' s
FULL OUTER JOIN
' + @DestinationTable + ' d ON s.EmployeeID = d.EmployeeID
WHERE
s.EmployeeID IS NULL OR d.EmployeeID IS NULL OR
s.FirstName <> d.FirstName OR s.LastName <> d.LastName OR
s.Email <> d.Email;';
EXEC(@SQL);
END;
-- Execute the procedure
EXEC CompareEmployeeTables 'Employees_Source', 'Employees_Destination';3.7.4. Considerations
- Flexibility: Custom scripts offer maximum flexibility for complex comparisons.
- Complexity: Developing and maintaining custom scripts can be complex and time-consuming.
- Security: Ensure proper security measures are in place to prevent SQL injection vulnerabilities.
4. Optimizing Performance for Table Comparison
4.1. Indexing
4.1.1. Importance of Indexing
Proper indexing can significantly improve the performance of table comparison queries. Indexes speed up data retrieval by allowing the database engine to quickly locate specific rows.
4.1.2. Creating Indexes
Create indexes on columns used in JOIN conditions and WHERE clauses.
CREATE INDEX IX_EmployeeID ON Employees_Source (EmployeeID);
CREATE INDEX IX_EmployeeID ON Employees_Destination (EmployeeID);4.2. Partitioning
4.2.1. Partitioning Large Tables
Partitioning involves dividing a large table into smaller, more manageable pieces. This can improve query performance by reducing the amount of data that needs to be scanned.
4.2.2. Implementing Partitioning
Partitioning can be based on a range of values, such as dates or IDs.
-- Example of partitioning in SQL Server
CREATE PARTITION FUNCTION PF_EmployeeID (INT)
AS RANGE LEFT FOR VALUES (1000, 2000, 3000);
CREATE PARTITION SCHEME PS_EmployeeID
AS PARTITION PF_EmployeeID
TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY]);
CREATE TABLE Employees_Source (
EmployeeID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100)
) ON PS_EmployeeID(EmployeeID);4.3. Query Optimization
4.3.1. Using Query Hints
Query hints can provide the database engine with additional information about how to execute a query.
SELECT
/*+ HASH JOIN */
A.*,
B.*
FROM
TableA A
JOIN
TableB B ON A.column1 = B.column1;4.3.2. Rewriting Queries
Rewriting queries can sometimes improve performance. For example, using EXISTS instead of COUNT can be more efficient in certain scenarios.
SELECT
*
FROM
TableA A
WHERE
EXISTS (SELECT 1 FROM TableB B WHERE A.column1 = B.column1);4.4. Parallel Processing
4.4.1. Enabling Parallelism
Parallel processing involves dividing a query into smaller tasks that can be executed simultaneously. This can significantly improve performance for large tables.
4.4.2. Configuring Parallelism
Configure the maximum degree of parallelism (MAXDOP) to control the number of processors used for parallel execution.
-- Example in SQL Server
sp_configure 'show advanced options', 1;
GO
RECONFIGURE;
GO
sp_configure 'max degree of parallelism', 8;
GO
RECONFIGURE;
GO5. Best Practices for SQL Table Comparison
5.1. Understand Your Data
Before comparing tables, understand the data types, relationships, and constraints. This will help you choose the most appropriate comparison method.
5.2. Use Primary Keys
Use primary keys to establish relationships between tables. This ensures accurate and efficient comparisons.
5.3. Handle Null Values
Properly handle NULL values in your queries. Use ISNULL or COALESCE to avoid unexpected results.
5.4. Test Your Queries
Always test your comparison queries on a development or test environment before running them on a production system.
5.5. Monitor Performance
Monitor the performance of your comparison queries and make adjustments as needed. Use query profiling tools to identify bottlenecks.
5.6. Document Your Approach
Document your table comparison approach, including the methods used, the reasons for choosing those methods, and any optimizations applied.
6. Common Pitfalls to Avoid
6.1. Incorrect Join Conditions
Using incorrect join conditions can lead to inaccurate results. Double-check your join conditions to ensure they are correct.
6.2. Ignoring Data Types
Ignoring data types can lead to comparison errors. Ensure that you are comparing columns with compatible data types.
6.3. Overlooking Null Values
Overlooking NULL values can lead to unexpected results. Use ISNULL or COALESCE to handle NULL values properly.
6.4. Neglecting Performance
Neglecting performance can lead to slow query execution times. Optimize your queries and indexes to ensure efficient comparisons.
6.5. Security Vulnerabilities
Failing to address security vulnerabilities can expose your data to unauthorized access. Use parameterized queries or stored procedures to prevent SQL injection attacks.
7. Tools for SQL Table Comparison
7.1. SQL Server Management Studio (SSMS)
SSMS provides a graphical interface for comparing and synchronizing databases.
7.2. Azure Data Studio
Azure Data Studio is a cross-platform database tool that supports SQL Server and other databases.
7.3. Third-Party Tools
Various third-party tools are available for SQL table comparison, such as Red Gate SQL Compare, ApexSQL Data Diff, and DBVisualizer.
8. Real-World Examples
8.1. Data Migration Verification
After migrating a database to a new server, use the EXCEPT operator to verify that all tables and data have been transferred correctly.
SELECT column1, column2, ...
FROM OldDatabase.dbo.TableA
EXCEPT
SELECT column1, column2, ...
FROM NewDatabase.dbo.TableA;8.2. ETL Process Validation
During an ETL process, use JOIN operations to validate that the data in the target table matches the data in the source table.
SELECT
s.column1,
s.column2,
t.column1,
t.column2
FROM
SourceTable s
JOIN
TargetTable t ON s.column1 = t.column1
WHERE
s.column2 <> t.column2;8.3. Data Quality Monitoring
Regularly compare tables to detect data quality issues, such as inconsistencies or errors.
SELECT
COALESCE(A.column1, B.column1) AS column1,
A.column2 AS SourceValue,
B.column2 AS DestinationValue
FROM
TableA A
FULL OUTER JOIN
TableB B ON A.column1 = B.column1
WHERE
A.column2 <> B.column2;9. Case Studies
9.1. Financial Institution Data Reconciliation
A financial institution needed to reconcile data between two databases after a merger. They used a combination of JOIN operations and custom scripts to identify and resolve discrepancies.
9.2. Healthcare Provider Data Migration
A healthcare provider migrated their patient data to a new system. They used the EXCEPT operator and hashing techniques to verify that all data was transferred accurately.
9.3. E-Commerce Platform Inventory Synchronization
An e-commerce platform needed to synchronize inventory data between multiple systems. They used window functions and custom procedures to ensure that inventory levels were consistent across all platforms.
10. Frequently Asked Questions (FAQ)
10.1. What is the best method for comparing two SQL tables?
The best method depends on the specific requirements, such as the size of the tables, the complexity of the comparison, and the available resources. EXCEPT, JOIN operations, hashing, and custom scripts are all viable options.
10.2. How can I improve the performance of table comparison queries?
Improve performance by using indexes, partitioning large tables, optimizing queries, and enabling parallel processing.
10.3. How do I handle NULL values when comparing tables?
Use ISNULL or COALESCE to handle NULL values properly. This ensures that NULL values are treated consistently in your comparisons.
10.4. What are the common pitfalls to avoid when comparing tables?
Avoid incorrect join conditions, ignoring data types, overlooking NULL values, neglecting performance, and security vulnerabilities.
10.5. Can I use third-party tools for SQL table comparison?
Yes, various third-party tools are available for SQL table comparison, such as Red Gate SQL Compare, ApexSQL Data Diff, and DBVisualizer.
10.6. How do I compare tables with different schemas?
Comparing tables with different schemas requires careful mapping of columns and data types. Custom scripts or ETL tools can be used to handle schema differences.
10.7. What is the difference between EXCEPT and INTERSECT?
EXCEPT returns rows from the first query that are not present in the second query, while INTERSECT returns rows that are common to both queries.
10.8. How do I compare tables with millions of rows?
Comparing tables with millions of rows requires careful optimization. Use indexing, partitioning, and parallel processing to improve performance.
10.9. What is the role of primary keys in table comparison?
Primary keys are essential for establishing relationships between tables and ensuring accurate and efficient comparisons.
10.10. How do I ensure data integrity during table comparison?
Ensure data integrity by using proper validation techniques, testing your queries thoroughly, and monitoring performance.
11. Conclusion
Comparing two SQL tables is a critical task for data management, data warehousing, and data migration. By understanding the various methods, best practices, and potential pitfalls, you can effectively compare tables and ensure data integrity. Whether you choose to use EXCEPT, JOIN operations, hashing, or custom scripts, the key is to understand your data and choose the right approach for your specific needs. For more in-depth comparisons and expert advice, visit COMPARE.EDU.VN, your ultimate resource for making informed decisions. If you have any questions or need further assistance, contact us at 333 Comparison Plaza, Choice City, CA 90210, United States, Whatsapp: +1 (626) 555-9090, or visit our website compare.edu.vn.
By following this comprehensive guide, you’ll be well-equipped to tackle any SQL table comparison challenge. Remember, choosing the right method and optimizing your queries are essential for achieving accurate and efficient results.