Comparing rows in SQL from the same table is a key skill for data analysis, trend identification, and uncovering relationships within your data. COMPARE.EDU.VN provides detailed guides on efficient querying techniques. This article explores methods using self-joins and conditional queries to extract valuable insights. Learn how to perform row comparisons, identify data patterns, and leverage these techniques for real-world data analysis. Let’s dive into SQL data analysis and conditional logic.
1. Understanding the Need for Row Comparison
Why is comparing rows within the same SQL table important? This technique offers several key benefits:
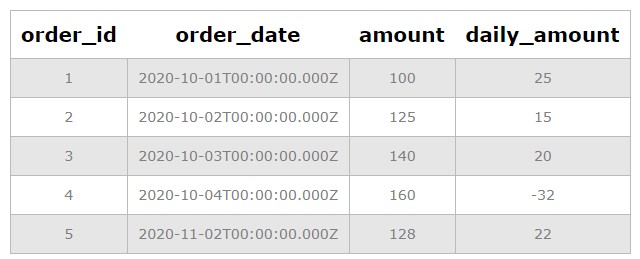
- Trend Analysis: Track changes over time by comparing consecutive rows (e.g., daily sales figures).
- Anomaly Detection: Identify outliers by comparing a row’s values to the average or expected values in other rows.
- Data Validation: Ensure data consistency by comparing related rows (e.g., verifying that a customer’s address is consistent across multiple orders).
- Relationship Discovery: Find connections between data points within the same table (e.g., identifying customers who live in the same city).
Comparing rows enables deeper insights and more effective data-driven decision-making.
2. Core Techniques for Row Comparison
SQL provides several methods for comparing rows, each suited to different scenarios:
2.1 Self-Joins
A self-join involves joining a table to itself. This allows you to compare rows within the same table based on specified criteria. This is one of the most common techniques when working with SQL databases.
- How it Works: You create two aliases for the same table and then join them based on a related column.
- Use Cases:
- Finding customers in the same city
- Comparing sales amounts between different orders from the same customer
- Identifying employees who report to the same manager
2.2 Window Functions
Window functions perform calculations across a set of table rows that are related to the current row.
- How it Works: You can use functions like
LAG()andLEAD()to access previous and subsequent rows, enabling comparisons. - Use Cases:
- Calculating the difference between consecutive values in a time series
- Finding the top N values within a group
- Calculating running totals or moving averages
2.3 Subqueries
Subqueries are queries nested inside another query. They can be used to retrieve values for comparison purposes.
- How it Works: A subquery can select a value from the same table based on certain conditions, which can then be used in the outer query to compare with other rows.
- Use Cases:
- Finding rows where a specific column’s value is greater than the average value for that column
- Identifying rows that match criteria defined by another selection within the same table
2.4 Conditional Aggregation
Conditional aggregation involves using CASE statements within aggregate functions to perform comparisons.
- How it Works: You can group rows based on certain criteria and then use
CASEstatements to compare values within each group. - Use Cases:
- Comparing the total sales for different product categories
- Identifying groups with values exceeding a certain threshold
3. Detailed Examples of Row Comparison Techniques
Let’s explore specific examples of each technique, using a sample “employees” table with the following structure:
| employee_id | employee_name | department | salary | hire_date |
|---|---|---|---|---|
| 1 | John Smith | Sales | 60000 | 2022-01-15 |
| 2 | Alice Johnson | Marketing | 70000 | 2021-05-20 |
| 3 | Bob Williams | Sales | 62000 | 2022-03-10 |
| 4 | Emily Brown | IT | 80000 | 2020-11-01 |
| 5 | David Lee | Marketing | 68000 | 2021-08-01 |
| 6 | Sarah Taylor | IT | 82000 | 2020-09-15 |
| 7 | Michael Clark | Sales | 65000 | 2022-05-01 |
| 8 | Jessica White | Marketing | 72000 | 2021-02-10 |
| 9 | Kevin Hall | IT | 78000 | 2020-12-01 |
| 10 | Ashley King | Sales | 61000 | 2022-02-20 |
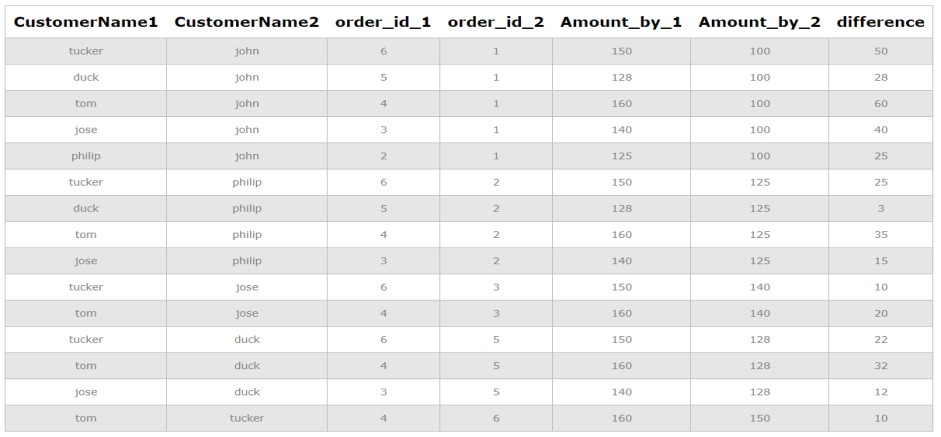
3.1 Using Self-Joins to Find Employees in the Same Department
This query identifies employees who work in the same department:
SELECT
e1.employee_name AS employee1,
e2.employee_name AS employee2,
e1.department
FROM
employees e1
INNER JOIN
employees e2 ON e1.department = e2.department AND e1.employee_id != e2.employee_id
ORDER BY
e1.department, employee1;- Explanation: The query joins the
employeestable to itself, aliased ase1ande2. TheONcondition matches rows where thedepartmentis the same, and theemployee_idis different (to avoid matching an employee to themselves). This finds all pairs of employees within the same department.
3.2 Using Window Functions to Calculate Salary Difference with Previous Employee Hired
This query calculates the salary difference between each employee and the employee hired immediately before them:
SELECT
employee_name,
hire_date,
salary,
salary - LAG(salary, 1, 0) OVER (ORDER BY hire_date) AS salary_difference
FROM
employees;- Explanation: The
LAG()function accesses thesalaryvalue from the previous row, ordered byhire_date. TheOVER (ORDER BY hire_date)clause specifies the order in which the rows are processed. The third argument,0, is the default value returned if there is no previous row.
3.3 Using Subqueries to Find Employees with Salaries Above the Average
This query identifies employees whose salary is greater than the average salary in the company:
SELECT
employee_name,
salary
FROM
employees
WHERE
salary > (SELECT AVG(salary) FROM employees);- Explanation: The subquery
(SELECT AVG(salary) FROM employees)calculates the average salary of all employees. The outer query then selects theemployee_nameandsalaryof those employees whosesalaryis greater than this average.
3.4 Using Conditional Aggregation to Compare Salaries by Department
This query compares the total salary for each department to a specific value:
SELECT
department,
SUM(CASE WHEN salary > 70000 THEN salary ELSE 0 END) AS total_salary_above_70000,
SUM(CASE WHEN salary <= 70000 THEN salary ELSE 0 END) AS total_salary_below_70000
FROM
employees
GROUP BY
department;- Explanation: The query groups the employees by
department. Within each group, theCASEstatements conditionally sum thesalarybased on whether it is greater than 70000 or not. This allows comparison of salary distribution within each department.
4. Advanced Techniques and Considerations
Beyond the basic techniques, consider these advanced approaches and factors:
4.1 Handling NULL Values
When comparing rows, NULL values can cause unexpected results. Use the IS NULL and IS NOT NULL operators, or the COALESCE() function, to handle NULL values appropriately.
- Example:
SELECT employee_name, COALESCE(salary, 0) AS salary FROM employees WHERE COALESCE(salary, 0) > 50000;This query treats
NULLsalaries as 0 for comparison purposes.
4.2 Performance Optimization
Comparing rows can be resource-intensive, especially on large tables. Optimize your queries by:
- Using Indexes: Ensure that the columns used in the
JOINorWHEREclauses are indexed. - Limiting Data: Reduce the number of rows processed by using appropriate
WHEREclauses to filter data. - Avoiding Complex Calculations: Simplify your calculations as much as possible to reduce processing time.
4.3 Combining Techniques
Complex comparisons may require combining multiple techniques. For example, you might use a self-join to find related rows and then use window functions to calculate differences between those rows.
4.4 Temporal Data Comparison
When working with temporal data, you might want to compare rows based on time intervals. SQL offers functions like DATE_ADD, DATE_SUB, and DATEDIFF to facilitate these comparisons.
- Example:
SELECT o1.order_id, o1.order_date, o2.order_id, o2.order_date FROM orders o1 JOIN orders o2 ON o1.customer_id = o2.customer_id WHERE o2.order_date > o1.order_date AND o2.order_date <= DATE_ADD(o1.order_date, INTERVAL 30 DAY);This query finds orders from the same customer within a 30-day period.
5. Real-World Applications
The row comparison techniques are applicable across many industries and use cases:
- Finance: Detecting fraudulent transactions by comparing transaction patterns to historical data.
- E-commerce: Recommending products based on items previously purchased by the same customer.
- Healthcare: Identifying patients with similar medical histories or treatment outcomes.
- Manufacturing: Detecting anomalies in sensor data to predict equipment failure.
- Marketing: Analyzing customer behavior to personalize marketing campaigns.
6. Common Mistakes to Avoid
When comparing rows, avoid these common pitfalls:
- Incorrect Join Conditions: Ensure that your
JOINconditions accurately reflect the relationship between rows. - Ignoring NULL Values: Always consider how
NULLvalues will affect your comparisons. - Performance Issues: Be mindful of the performance implications of your queries, especially on large tables.
- Incorrectly Using Window Functions: Ensure that your
OVER()clauses correctly define the window of rows to be processed.
7. Optimizing Your SQL Queries for Row Comparison
7.1 Leveraging Indexes
Indexes can significantly speed up your queries, particularly when joining tables or filtering data. Make sure that the columns you use in JOIN and WHERE clauses are indexed.
CREATE INDEX idx_department ON employees (department);
CREATE INDEX idx_hire_date ON employees (hire_date);
CREATE INDEX idx_salary ON employees (salary);7.2 Partitioning Tables
For very large tables, consider partitioning the table to improve query performance. Partitioning divides a table into smaller, more manageable pieces.
ALTER TABLE orders
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION p2022 VALUES LESS THAN (2023),
PARTITION pfuture VALUES LESS THAN MAXVALUE
);7.3 Using Temporary Tables
For complex queries that involve multiple steps, using temporary tables can help break down the logic and improve performance.
CREATE TEMPORARY TABLE temp_salaries AS
SELECT
department,
AVG(salary) AS avg_salary
FROM
employees
GROUP BY
department;
SELECT
e.employee_name,
e.salary,
t.avg_salary
FROM
employees e
JOIN
temp_salaries t ON e.department = t.department
WHERE
e.salary > t.avg_salary;7.4 Query Hints
SQL Server provides query hints that can guide the query optimizer to choose a specific execution plan. Use these hints with caution, as they can sometimes lead to suboptimal performance if not used correctly.
SELECT
e1.employee_name,
e2.employee_name
FROM
employees e1
JOIN
employees e2 WITH (INDEX(idx_department)) ON e1.department = e2.department
WHERE
e1.salary > 70000;8. Advanced Window Function Techniques
8.1 Rank and Dense_Rank
These functions assign a rank to each row within a partition based on the specified order.
SELECT
employee_name,
salary,
department,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS salary_rank,
DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS salary_dense_rank
FROM
employees;RANK() assigns ranks with gaps (e.g., 1, 2, 2, 4), while DENSE_RANK() assigns consecutive ranks (e.g., 1, 2, 2, 3).
8.2 Ntile
This function divides the rows in a partition into a specified number of groups.
SELECT
employee_name,
salary,
department,
NTILE(4) OVER (PARTITION BY department ORDER BY salary DESC) AS salary_quartile
FROM
employees;This divides employees in each department into four quartiles based on their salary.
8.3 First_Value and Last_Value
These functions return the first and last values in a partition, respectively.
SELECT
employee_name,
salary,
department,
FIRST_VALUE(employee_name) OVER (PARTITION BY department ORDER BY salary DESC) AS highest_paid_employee,
LAST_VALUE(employee_name) OVER (PARTITION BY department ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lowest_paid_employee
FROM
employees;This shows the highest and lowest paid employees in each department.
9. Comparing Data Across Multiple Tables
While the focus has been on comparing rows within the same table, it’s also common to compare data across multiple tables. This often involves using JOIN operations in conjunction with the techniques discussed earlier.
9.1 Example: Comparing Sales Data with Customer Data
Suppose you have two tables: sales and customers.
sales table:
| sale_id | customer_id | sale_date | amount |
|---|---|---|---|
| 1 | 101 | 2023-01-01 | 100 |
| 2 | 102 | 2023-01-01 | 150 |
| 3 | 101 | 2023-01-05 | 200 |
| 4 | 103 | 2023-01-10 | 120 |
customers table:
| customer_id | customer_name | city |
|---|---|---|
| 101 | John Doe | New York |
| 102 | Alice Smith | London |
| 103 | Bob Johnson | Paris |
To compare sales amounts with customer locations, you can use a JOIN:
SELECT
c.customer_name,
c.city,
SUM(s.amount) AS total_sales
FROM
sales s
JOIN
customers c ON s.customer_id = c.customer_id
GROUP BY
c.customer_name,
c.city;This query calculates the total sales for each customer and displays their city.
10. Security Considerations
When comparing rows, especially in sensitive datasets, be mindful of security. Ensure that you are not exposing sensitive information unintentionally.
10.1 Data Masking
Use data masking techniques to protect sensitive data while still allowing for meaningful comparisons.
10.2 Role-Based Access Control
Implement role-based access control to restrict access to sensitive data based on user roles.
10.3 Auditing
Enable auditing to track who is accessing and comparing data. This can help detect and prevent unauthorized access.
11. SQL Standards and Compatibility
Different database systems (e.g., MySQL, PostgreSQL, SQL Server, Oracle) may have slight variations in syntax and available functions. Always refer to the documentation for your specific database system.
11.1 ANSI SQL
ANSI SQL is a standard that aims to provide a common language for interacting with relational databases. While most database systems support ANSI SQL, they often include extensions and proprietary features.
11.2 Testing
Test your queries on different database systems to ensure compatibility. Use conditional logic or database-specific functions to handle any differences.
12. Conclusion: Mastering SQL Row Comparisons for Data Excellence
Comparing rows in SQL from the same table is a vital skill for anyone working with databases. By mastering techniques like self-joins, window functions, subqueries, and conditional aggregation, you can unlock valuable insights from your data. Remember to optimize your queries for performance, handle NULL values appropriately, and be mindful of security considerations. By following the guidelines and examples presented in this article, you’ll be well-equipped to tackle even the most complex row comparison challenges.
Are you looking to make more informed decisions based on comprehensive data comparisons? Visit COMPARE.EDU.VN today. Our platform offers detailed and objective comparisons to help you evaluate your options and choose the best solutions.
Address: 333 Comparison Plaza, Choice City, CA 90210, United States
WhatsApp: +1 (626) 555-9090
Website: compare.edu.vn
13. FAQ – How to Compare Rows in SQL From Same Table?
13.1 What is a self-join in SQL?
A self-join is when you join a table to itself. This is useful for comparing rows within the same table.
13.2 How can I compare consecutive rows in SQL?
You can use window functions like LAG() and LEAD() to access previous and subsequent rows for comparison.
13.3 How do I handle NULL values when comparing rows?
Use IS NULL, IS NOT NULL, or COALESCE() to handle NULL values and avoid unexpected results.
13.4 What are some performance optimization tips for comparing rows?
Use indexes, limit the amount of data processed, and avoid complex calculations.
13.5 Can I compare data across multiple tables?
Yes, use JOIN operations in conjunction with the row comparison techniques discussed in this article.
13.6 How do I find employees in the same department using SQL?
Use a self-join to compare the department column for different employees.
13.7 What is conditional aggregation and how can I use it for row comparison?
Conditional aggregation involves using CASE statements within aggregate functions to compare values within groups.
13.8 How can I find employees with salaries above the average salary in the company?
Use a subquery to calculate the average salary and then compare each employee’s salary to that average.
13.9 What are window functions and how are they useful for row comparison?
Window functions perform calculations across a set of table rows that are related to the current row, allowing you to compare values across rows.
13.10 How do I ensure security when comparing sensitive data in SQL?
Use data masking, role-based access control, and auditing to protect sensitive information.