COMPARE.EDU.VN is dedicated to providing comprehensive and objective comparisons, and understanding the nuances of statistical testing is crucial. This article delves into the world of statistical analysis, focusing on A Quasi-exact Test For Comparing Two Binomial Proportions, offering you a clear path to make informed decisions about your data. Explore methods for binomial proportion comparison and discover the strengths and weaknesses inherent in various approaches.
1. Introduction to Comparing Binomial Proportions
Comparing two binomial proportions is a fundamental task in many fields, from medical research to marketing analytics. It involves determining whether the difference between the proportions of successes in two independent groups is statistically significant. This comparison allows researchers and analysts to draw meaningful conclusions about the effectiveness of treatments, the preferences of customers, or the impact of interventions. The core question lies in discerning a real difference from mere chance variation. Choosing the right statistical test is paramount to ensuring reliable results and avoiding misleading interpretations, enhancing your data-driven decision-making process. This exploration of proportion comparison methods will empower you to analyze your data with greater confidence.
1.1 The Importance of Choosing the Right Test
Selecting the appropriate statistical test is crucial for obtaining accurate and reliable results when comparing two binomial proportions. Different tests have varying assumptions and sensitivities, and using an unsuitable test can lead to incorrect conclusions. For instance, some tests are more conservative, meaning they are less likely to detect a true difference, while others are more prone to Type I errors, falsely identifying a difference when none exists. The choice of test should be guided by the characteristics of the data, such as sample size, the magnitude of the proportions, and the presence of paired or independent samples. A thoughtful selection process ensures the validity of the findings and enhances the credibility of the research or analysis. Ultimately, the right test provides a solid foundation for making informed decisions based on sound statistical evidence. Consider exploring resources at COMPARE.EDU.VN for guidance on selecting the best test for your specific scenario.
1.2 Understanding Type I and Type II Errors
In hypothesis testing, two types of errors can occur: Type I and Type II errors. A Type I error, also known as a false positive, happens when we reject the null hypothesis when it is actually true. In the context of comparing binomial proportions, this means concluding that there is a significant difference between the two proportions when, in reality, there is no difference. The probability of committing a Type I error is denoted by α (alpha), often set at 0.05, meaning there is a 5% chance of falsely rejecting the null hypothesis.
Conversely, a Type II error, also known as a false negative, occurs when we fail to reject the null hypothesis when it is false. In this context, it means failing to detect a significant difference between the two proportions when a real difference exists. The probability of committing a Type II error is denoted by β (beta). The power of a test, defined as 1 – β, represents the probability of correctly rejecting the null hypothesis when it is false.
Minimizing both Type I and Type II errors is essential for robust statistical inference. While controlling the Type I error rate is typically the primary focus, it is also important to consider the power of the test to ensure that true differences are detected. Factors such as sample size, effect size, and the choice of statistical test can influence both Type I and Type II error rates. A thorough understanding of these errors is crucial for interpreting statistical results and making informed decisions.
2. Overview of McNemar’s Test and Its Variations
McNemar’s test is a statistical test used to compare two related or paired proportions. It is particularly suitable for analyzing data from matched pairs designs, where each subject or unit contributes two observations. In such designs, the observations are not independent, and traditional tests for comparing independent proportions are not appropriate. McNemar’s test focuses on the discordant pairs, which are the pairs where the outcomes differ between the two conditions.
2.1 The Basic McNemar Test
The basic McNemar test is based on a 2×2 contingency table that classifies the paired observations into four categories: (1) both observations are successes, (2) the first observation is a success and the second is a failure, (3) the first observation is a failure and the second is a success, and (4) both observations are failures. The test statistic is calculated using only the discordant pairs (categories 2 and 3) and follows a chi-squared distribution with one degree of freedom.
The null hypothesis of McNemar’s test is that the two proportions are equal, meaning that the probability of a success is the same for both conditions. The test determines whether the observed difference in proportions is statistically significant, taking into account the paired nature of the data. The basic McNemar test is simple and widely used but can be conservative, especially with small sample sizes. This conservativeness can lead to a reduced power to detect real differences.
2.2 Asymptotic McNemar Test
The asymptotic McNemar test is a variation of the basic McNemar test that uses a continuous approximation to the discrete distribution of the test statistic. This approximation is valid when the sample size is sufficiently large. The test statistic follows a chi-squared distribution with one degree of freedom, similar to the basic McNemar test.
However, the asymptotic McNemar test can be unreliable when the sample size is small or when the proportions are extreme (close to 0 or 1). In such cases, the chi-squared approximation may not be accurate, leading to inflated Type I error rates (false positives). The asymptotic test is computationally simple and widely implemented in statistical software packages but should be used with caution when the sample size is limited.
2.3 McNemar Test with Continuity Correction (CC)
To address the conservativeness of the basic McNemar test, a continuity correction (CC) is often applied. The McNemar test with continuity correction adjusts the test statistic by reducing the absolute difference between the observed and expected values by 0.5 before squaring. This adjustment aims to improve the accuracy of the chi-squared approximation, especially with small sample sizes.
However, while the continuity correction can reduce the conservativeness of the test, it can also make the test overly conservative in some cases. This overcorrection can lead to reduced power, making it more difficult to detect real differences between the proportions. The McNemar test with continuity correction is a common approach but requires careful consideration of its potential impact on the test’s performance.
2.4 McNemar Mid-p Test
The McNemar mid-p test is a modification of the McNemar test that aims to provide a more accurate p-value, particularly when the sample size is small. The mid-p test calculates the p-value by taking half of the probability of the observed result plus the probability of more extreme results. This approach reduces the conservativeness of the traditional McNemar test without inflating the Type I error rate.
The mid-p test offers a compromise between the conservativeness of exact tests and the potential inaccuracy of asymptotic tests. It is generally recommended for situations where the sample size is not large enough to rely on asymptotic approximations but where exact tests may be too conservative. The McNemar mid-p test provides a more balanced approach to comparing paired proportions.
3. Exact Unconditional Test: An Alternative Approach
The exact unconditional test is an alternative approach to comparing two binomial proportions that does not rely on asymptotic approximations or continuity corrections. It directly calculates the exact p-value by considering all possible outcomes under the null hypothesis. This approach is particularly useful when the sample size is small or when the proportions are extreme.
3.1 Principles of the Exact Unconditional Test
The exact unconditional test involves calculating the probability of observing the data or more extreme data under the null hypothesis. This calculation requires considering all possible combinations of successes and failures in the two groups, while holding the total sample size constant. The p-value is then computed as the sum of the probabilities of all outcomes that are as or more extreme than the observed data.
The exact unconditional test is computationally intensive, especially for large sample sizes, but it provides an accurate p-value without relying on approximations. It is a valuable tool for situations where the validity of asymptotic tests is questionable. The exact unconditional test ensures reliable results by avoiding the limitations of approximate methods.
3.2 Advantages of the Exact Unconditional Test
The exact unconditional test offers several advantages over other methods for comparing binomial proportions. First, it provides an exact p-value, which is particularly important when the sample size is small or when the proportions are extreme. Second, it does not rely on asymptotic approximations or continuity corrections, which can be inaccurate in some cases. Third, it is less conservative than the McNemar exact conditional test, leading to greater power to detect real differences.
The exact unconditional test is a robust and reliable approach that can be used in a wide range of situations. Its accuracy and lack of reliance on approximations make it a preferred choice when the validity of other tests is uncertain. The advantages of the exact unconditional test make it a valuable tool for statistical inference.
3.3 Limitations and Computational Considerations
Despite its advantages, the exact unconditional test also has some limitations. One major limitation is its computational intensity. Calculating the exact p-value requires considering all possible outcomes, which can be time-consuming, especially for large sample sizes. This computational burden can make the exact unconditional test impractical for some applications.
Another consideration is that the exact unconditional test can be sensitive to the choice of the null hypothesis. In some cases, different null hypotheses can lead to different p-values, which can complicate the interpretation of the results. Despite these limitations, the exact unconditional test remains a valuable tool for comparing binomial proportions when accuracy and reliability are paramount.
4. Quasi-Exact Test: Balancing Accuracy and Computational Efficiency
To address the limitations of both asymptotic and exact tests, researchers have developed quasi-exact tests. These tests aim to strike a balance between accuracy and computational efficiency, providing reliable results without the computational burden of exact tests.
4.1 Definition and Characteristics of Quasi-Exact Tests
Quasi-exact tests are statistical tests that approximate the exact p-value by using a combination of asymptotic and exact methods. These tests typically involve calculating an approximate p-value using an asymptotic test and then adjusting it based on the results of an exact test. The adjustment is designed to improve the accuracy of the approximate p-value, especially when the sample size is small or when the proportions are extreme.
Quasi-exact tests offer a practical compromise between accuracy and computational efficiency. They provide more reliable results than asymptotic tests without the computational intensity of exact tests. The characteristics of quasi-exact tests make them a valuable tool for statistical inference.
4.2 How Quasi-Exact Tests Improve Accuracy
Quasi-exact tests improve accuracy by incorporating information from both asymptotic and exact methods. The asymptotic test provides a computationally efficient approximation of the p-value, while the exact test provides a more accurate p-value for small sample sizes or extreme proportions. The quasi-exact test combines these two approaches by adjusting the asymptotic p-value based on the results of the exact test.
This adjustment typically involves calculating a correction factor that accounts for the difference between the asymptotic and exact p-values. The corrected p-value is then used to make inferences about the difference between the two proportions. By combining the strengths of both asymptotic and exact methods, quasi-exact tests provide more reliable results than either method alone. The improvement in accuracy offered by quasi-exact tests makes them a valuable tool for statistical analysis.
4.3 Scenarios Where Quasi-Exact Tests Are Most Useful
Quasi-exact tests are particularly useful in scenarios where the sample size is small or when the proportions are extreme. In these situations, asymptotic tests can be unreliable, while exact tests can be computationally intensive. Quasi-exact tests provide a practical alternative by offering more accurate results than asymptotic tests without the computational burden of exact tests.
These tests are also valuable when analyzing complex data sets with multiple comparisons or when performing simulations. The computational efficiency of quasi-exact tests allows researchers to analyze large amounts of data in a reasonable amount of time. The usefulness of quasi-exact tests in these scenarios makes them a valuable tool for statistical inference.
5. Evaluating Type I Error Rates
Type I error rate, also known as the significance level (α), is the probability of rejecting the null hypothesis when it is true. In the context of comparing two binomial proportions, a Type I error occurs when we conclude that there is a significant difference between the two proportions when, in reality, there is no difference. Evaluating Type I error rates is crucial for assessing the validity of statistical tests.
5.1 Understanding Type I Error in Hypothesis Testing
Type I error is a fundamental concept in hypothesis testing. It represents the risk of falsely concluding that an effect or difference exists when it does not. The Type I error rate is typically set at 0.05, meaning there is a 5% chance of committing a Type I error. Controlling the Type I error rate is essential for ensuring the reliability of statistical results.
When comparing two binomial proportions, a Type I error can have serious consequences. For example, in a clinical trial, a Type I error could lead to the false conclusion that a new treatment is effective when it is not. Therefore, it is crucial to choose a statistical test that maintains the Type I error rate at the desired level. Understanding Type I error is crucial for making informed decisions based on statistical evidence.
5.2 Factors Influencing Type I Error Rates
Several factors can influence Type I error rates. One important factor is the sample size. As the sample size increases, the Type I error rate tends to decrease. Another factor is the choice of statistical test. Some tests are more conservative than others, meaning they are less likely to commit a Type I error.
The properties of the data can also influence Type I error rates. For example, if the data are not normally distributed or if the variances are unequal, the Type I error rate of some tests may be inflated. It is important to consider these factors when choosing a statistical test and interpreting the results. Awareness of these influencing factors allows for a more nuanced and accurate analysis.
5.3 Comparative Analysis of Type I Error Rates for Different Tests
Different statistical tests have different Type I error rates. The asymptotic McNemar test, for example, tends to have Type I error rates close to the nominal level (0.05) for most combinations of parameters. However, it can violate the level quite often, although not by much. The McNemar exact conditional test, on the other hand, has low Type I error rates and is quite conservative.
The exact unconditional test and the McNemar mid-p test perform similarly, with Type I error rates that are generally closer to the nominal level than the McNemar exact conditional test. When choosing a statistical test, it is important to consider the Type I error rates and select a test that maintains the desired level. A comparative analysis ensures that the chosen test is appropriate for the specific data and research question.
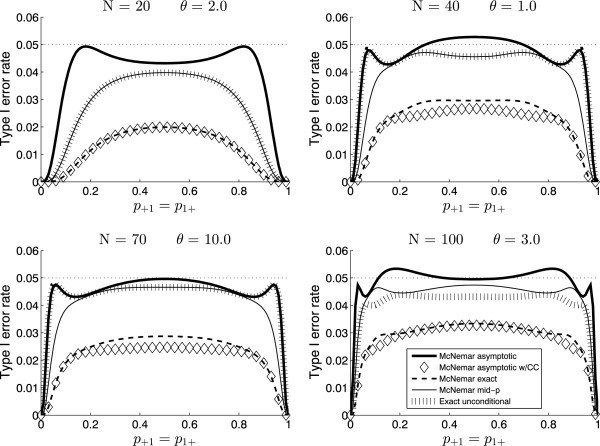 Type I error rates as functions of the probability of success.
Type I error rates as functions of the probability of success.
6. Assessing the Power of Tests
The power of a statistical test is the probability of correctly rejecting the null hypothesis when it is false. In the context of comparing two binomial proportions, the power represents the ability of the test to detect a real difference between the two proportions. Assessing the power of tests is crucial for ensuring that studies have adequate sensitivity to detect meaningful effects.
6.1 Definition and Importance of Statistical Power
Statistical power is a fundamental concept in hypothesis testing. It represents the probability of avoiding a Type II error, which occurs when we fail to reject the null hypothesis when it is false. A high-powered test is more likely to detect a real effect or difference, while a low-powered test may fail to detect a meaningful effect.
Adequate statistical power is essential for conducting rigorous and informative research. Studies with low power may produce inconclusive results, leading to wasted resources and potentially misleading conclusions. Therefore, it is crucial to assess the power of tests and ensure that studies are adequately powered to detect effects of interest. Understanding and prioritizing statistical power is vital for effective research design and analysis.
6.2 Factors Affecting the Power of a Test
Several factors can affect the power of a test. One important factor is the sample size. As the sample size increases, the power of the test also increases. Another factor is the effect size, which represents the magnitude of the difference between the two proportions. Larger effect sizes are easier to detect, leading to higher power.
The Type I error rate also affects the power of a test. Increasing the Type I error rate (e.g., from 0.05 to 0.10) will increase the power, but it will also increase the risk of committing a Type I error. The choice of statistical test can also influence the power. Some tests are more powerful than others for certain types of data. Considering these factors ensures that the test is optimized for detecting meaningful effects.
6.3 Power Comparison of Different Tests
Different statistical tests have different power characteristics. The asymptotic McNemar test, the McNemar mid-p test, and the exact unconditional test tend to have similar power, although the asymptotic test is slightly better than the other two tests. The McNemar exact conditional test and the asymptotic McNemar test with CC, on the other hand, have considerably lower power than the other tests.
When choosing a statistical test, it is important to consider the power characteristics and select a test that has adequate power to detect effects of interest. Power comparisons help in selecting the most appropriate test for the specific research question and data.
7. Real-World Examples and Applications
To illustrate the practical implications of choosing different statistical tests, let’s consider some real-world examples and applications. These examples will highlight the potential impact of test selection on the conclusions drawn from the data.
7.1 Medical Research: Comparing Treatment Outcomes
In medical research, comparing treatment outcomes is a common application of statistical tests for binomial proportions. For example, researchers may want to compare the proportion of patients who respond to a new treatment to the proportion of patients who respond to a standard treatment. The choice of statistical test can have a significant impact on the conclusions drawn from the study.
If the sample size is small or if the response rates are extreme, the asymptotic McNemar test may be unreliable, leading to inaccurate p-values. In such cases, the exact unconditional test or the McNemar mid-p test may be more appropriate. The selection of an appropriate test ensures the reliability and validity of the research findings.
7.2 Marketing Analytics: Assessing Customer Preferences
In marketing analytics, comparing customer preferences is another common application. For example, marketers may want to compare the proportion of customers who prefer a new product design to the proportion of customers who prefer the old design. The choice of statistical test can influence the marketing strategies and product development decisions.
If the sample size is large and the proportions are not extreme, the asymptotic McNemar test may be adequate. However, if the sample size is small or if the proportions are extreme, the exact unconditional test or the McNemar mid-p test may be more appropriate. The right test helps in making informed decisions based on customer preferences.
7.3 Public Health: Evaluating Intervention Effectiveness
In public health, evaluating the effectiveness of interventions is a critical task. For example, public health officials may want to compare the proportion of individuals who adopt a new health behavior after an intervention to the proportion of individuals who adopted the behavior before the intervention. The choice of statistical test can influence the public health policies and resource allocation.
The selection of a suitable test ensures that the evaluations are accurate and reliable, leading to effective public health strategies.
8. Guidelines for Selecting the Appropriate Test
Choosing the right statistical test for comparing two binomial proportions is essential for obtaining accurate and reliable results. Here are some guidelines to help you select the appropriate test for your specific situation.
8.1 Considering Sample Size and Proportion Values
The sample size and the values of the proportions are important factors to consider when choosing a statistical test. If the sample size is large and the proportions are not extreme (i.e., not close to 0 or 1), the asymptotic McNemar test may be adequate. However, if the sample size is small or if the proportions are extreme, the exact unconditional test or the McNemar mid-p test may be more appropriate.
For small sample sizes, exact tests or quasi-exact tests are generally recommended. These tests provide more accurate p-values than asymptotic tests when the sample size is limited. Consideration of these factors ensures the selection of the most suitable test for the given data.
8.2 Evaluating the Assumptions of Each Test
Each statistical test has its own assumptions that must be met in order for the test to be valid. It is important to evaluate the assumptions of each test and ensure that they are met by the data. For example, the asymptotic McNemar test assumes that the sample size is large enough for the chi-squared approximation to be accurate.
If the assumptions of a test are not met, the results of the test may be unreliable. In such cases, it may be necessary to use a different test or to transform the data to meet the assumptions. Evaluating the assumptions ensures the validity and reliability of the statistical analysis.
8.3 Balancing Accuracy and Computational Feasibility
When choosing a statistical test, it is important to balance accuracy and computational feasibility. Exact tests provide the most accurate p-values, but they can be computationally intensive, especially for large sample sizes. Asymptotic tests are computationally efficient, but they may be inaccurate when the sample size is small or when the proportions are extreme.
Quasi-exact tests offer a compromise between accuracy and computational efficiency. These tests provide more accurate results than asymptotic tests without the computational burden of exact tests. The choice of test should depend on the specific needs of the study and the available resources. Balancing these factors helps in selecting a test that is both accurate and practical.
9. Summary and Recommendations
In summary, comparing two binomial proportions is a fundamental task in many fields, and choosing the right statistical test is crucial for obtaining accurate and reliable results. Different tests have varying assumptions, Type I error rates, and power characteristics. It is important to consider these factors when selecting a test.
9.1 Key Takeaways on Test Selection
The asymptotic McNemar test is computationally efficient but may be unreliable when the sample size is small or when the proportions are extreme. The McNemar exact conditional test is conservative and has low power. The exact unconditional test provides accurate p-values but can be computationally intensive. The McNemar mid-p test offers a compromise between accuracy and computational efficiency.
When choosing a statistical test, consider the sample size, the values of the proportions, the assumptions of each test, and the need to balance accuracy and computational feasibility. These key takeaways help in making informed decisions about test selection.
9.2 General Recommendations for Researchers and Analysts
For researchers and analysts, it is generally recommended to use exact tests or quasi-exact tests when the sample size is small or when the proportions are extreme. These tests provide more accurate p-values than asymptotic tests in these situations. When the sample size is large and the proportions are not extreme, the asymptotic McNemar test may be adequate, but it is still important to check the assumptions of the test.
It is also important to consider the power of the test and ensure that studies are adequately powered to detect effects of interest. These general recommendations help in conducting rigorous and informative research.
9.3 The Role of COMPARE.EDU.VN in Providing Statistical Guidance
COMPARE.EDU.VN plays a vital role in providing statistical guidance to researchers and analysts. By offering comprehensive comparisons of different statistical tests, along with clear explanations of their assumptions, Type I error rates, and power characteristics, COMPARE.EDU.VN empowers users to make informed decisions about test selection.
COMPARE.EDU.VN also provides real-world examples and applications to illustrate the practical implications of choosing different tests. By offering this valuable resource, COMPARE.EDU.VN helps to promote sound statistical practice and improve the quality of research and analysis across various fields. Visit COMPARE.EDU.VN to explore more comparisons and make confident decisions.
10. Frequently Asked Questions (FAQ)
Here are some frequently asked questions about comparing two binomial proportions and selecting the appropriate statistical test:
10.1 What is a binomial proportion?
A binomial proportion is the proportion of successes in a fixed number of independent trials, where each trial has only two possible outcomes (success or failure).
10.2 Why is it important to choose the right statistical test for comparing two binomial proportions?
Choosing the right statistical test is crucial for obtaining accurate and reliable results. Different tests have varying assumptions, Type I error rates, and power characteristics.
10.3 What is McNemar’s test?
McNemar’s test is a statistical test used to compare two related or paired proportions. It is particularly suitable for analyzing data from matched pairs designs.
10.4 What is the difference between the asymptotic McNemar test and the exact McNemar test?
The asymptotic McNemar test uses a continuous approximation to the discrete distribution of the test statistic, while the exact McNemar test directly calculates the exact p-value by considering all possible outcomes.
10.5 When should I use the McNemar mid-p test?
The McNemar mid-p test is recommended for situations where the sample size is not large enough to rely on asymptotic approximations but where exact tests may be too conservative.
10.6 What is an exact unconditional test?
The exact unconditional test is an alternative approach to comparing two binomial proportions that does not rely on asymptotic approximations or continuity corrections.
10.7 What are the advantages of the exact unconditional test?
The advantages of the exact unconditional test include providing an exact p-value, not relying on asymptotic approximations, and being less conservative than the McNemar exact conditional test.
10.8 What are quasi-exact tests?
Quasi-exact tests are statistical tests that approximate the exact p-value by using a combination of asymptotic and exact methods.
10.9 How do I evaluate the assumptions of a statistical test?
To evaluate the assumptions of a statistical test, you should examine the properties of the data and ensure that they meet the assumptions of the test.
10.10 Where can I find more information about comparing two binomial proportions?
You can find more information about comparing two binomial proportions at COMPARE.EDU.VN, which provides comprehensive comparisons of different statistical tests and clear explanations of their properties.
Ready to make confident comparisons? Visit COMPARE.EDU.VN at 333 Comparison Plaza, Choice City, CA 90210, United States, or contact us on Whatsapp at +1 (626) 555-9090. Let compare.edu.vn be your guide to making informed decisions with clear, objective comparisons.
