A Comparative Study Of Classification Techniques In Data Mining Algorithms identifies the best approach for your specific data analysis needs, and COMPARE.EDU.VN helps you navigate these choices. It delivers a comprehensive overview that enhances predictive accuracy and operational efficiency through effective data categorization. This includes machine learning methods, statistical analysis, and data classification tools.
1. Introduction to Classification Techniques in Data Mining
Data mining involves extracting meaningful patterns and insights from large datasets. Classification is a crucial technique within data mining, used to categorize data into predefined classes. A comparative study of classification techniques evaluates the performance, advantages, and limitations of various algorithms. This helps in selecting the most appropriate technique for a specific task, enhancing the accuracy and efficiency of data analysis. This technique is very helpful in machine learning and statistical analysis.
1.1. What is Data Mining?
Data mining, also known as knowledge discovery, is the process of automatically discovering useful information from large data repositories. It involves several steps, including data cleaning, data integration, data selection, data transformation, data mining, pattern evaluation, and knowledge representation. Data mining techniques are used to uncover patterns, associations, anomalies, and dependencies in data, enabling businesses and organizations to make informed decisions.
1.2. What is Classification in Data Mining?
Classification is a data mining technique that assigns data instances to predefined categories or classes based on their attributes. It involves building a model from a training dataset with known class labels, and then using this model to predict the class labels of new, unseen data. Classification is used in a wide range of applications, including:
- Spam Detection: Identifying emails as spam or not spam.
- Medical Diagnosis: Diagnosing diseases based on patient symptoms and test results.
- Credit Risk Assessment: Assessing the creditworthiness of loan applicants.
- Customer Segmentation: Grouping customers into segments based on their purchasing behavior.
- Image Recognition: Identifying objects in images.
1.3. Why is a Comparative Study Important?
A comparative study of classification techniques is essential for several reasons:
- Algorithm Selection: Different classification algorithms have varying strengths and weaknesses. A comparative study helps in selecting the most suitable algorithm for a specific dataset and problem.
- Performance Evaluation: Evaluating the performance of different algorithms helps in understanding their accuracy, efficiency, and scalability.
- Optimization: Identifying the limitations of algorithms can lead to improvements and optimizations, enhancing their performance.
- Informed Decision Making: Providing a comprehensive overview of classification techniques empowers users to make informed decisions about which methods to use in their data mining projects.
2. Key Classification Algorithms
Several classification algorithms are widely used in data mining. Each algorithm has its unique approach and is suitable for different types of data and problems. Here are some of the key classification algorithms:
- Decision Trees
- Naïve Bayes
- Support Vector Machines (SVM)
- K-Nearest Neighbors (KNN)
- Artificial Neural Networks (ANN)
2.1. Decision Trees
Decision Trees are a popular classification technique that creates a tree-like structure to model decisions and their possible consequences. Each internal node in the tree represents a test on an attribute, each branch represents an outcome of the test, and each leaf node represents a class label. Decision Trees are easy to understand and interpret, making them a valuable tool for classification tasks.
2.1.1. ID3 Algorithm
ID3 (Iterative Dichotomiser 3) is one of the earliest decision tree algorithms. It uses information gain to determine the best attribute for splitting the data at each node. Information gain measures the reduction in entropy (uncertainty) after splitting the data on an attribute. The attribute with the highest information gain is chosen as the splitting attribute.
Working Steps of ID3 Algorithm:
- Calculate the entropy of the dataset.
- For each attribute, calculate the information gain.
- Select the attribute with the highest information gain as the splitting attribute.
- Create a decision tree node with the selected attribute.
- Split the dataset into subsets based on the values of the selected attribute.
- Recursively apply the ID3 algorithm to each subset.
2.1.2. C4.5 Algorithm
C4.5 is an extension of the ID3 algorithm that addresses some of its limitations. C4.5 can handle both continuous and discrete attributes, missing values, and pruning trees after construction. It uses gain ratio instead of information gain to select the splitting attribute. Gain ratio is a modification of information gain that reduces bias towards attributes with a large number of values.
Working Steps of C4.5 Algorithm:
- If all samples belong to the same class, create a leaf node with that class label.
- If no features provide any information gain, create a decision node using the expected value of the class.
- If an instance of a previously unseen class is encountered, create a decision node using the expected value.
- For each attribute, calculate the gain ratio.
- Select the attribute with the highest gain ratio as the splitting attribute.
- Create a decision tree node with the selected attribute.
- Split the dataset into subsets based on the values of the selected attribute.
- Recursively apply the C4.5 algorithm to each subset.
Advantages of Decision Trees:
- Easy to understand and interpret
- Can handle both categorical and numerical data
- Minimal data preparation required
Disadvantages of Decision Trees:
- Prone to overfitting
- Can be unstable (small changes in the data can lead to large changes in the tree)
- May not be suitable for complex relationships between attributes
 ID3 and C4.5 algorithms for decision tree generation in data mining
ID3 and C4.5 algorithms for decision tree generation in data mining
2.2. Naïve Bayes
Naïve Bayes is a probabilistic classifier based on Bayes’ theorem with a strong (naïve) independence assumption between the features. Despite its simplicity, Naïve Bayes can be surprisingly effective in many real-world applications, particularly in text classification and spam filtering.
2.2.1. Bayes’ Theorem
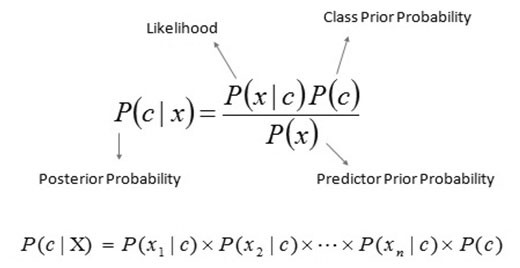
Bayes’ theorem provides a way of calculating the posterior probability P(c|x) from P(c), P(x), and P(x|c), where:
- P(c|x) is the posterior probability of class c given predictor x.
- P(c) is the prior probability of class c.
- P(x|c) is the likelihood, which is the probability of predictor x given class c.
- P(x) is the prior probability of predictor x.
Formula for Bayes’ Theorem:
P(c|x) = (P(x|c) P(c)) / P(x)*
2.2.2. Naïve Assumption
The “naïve” assumption in Naïve Bayes is that the effect of the value of a predictor (x) on a given class (c) is independent of the values of other predictors. This assumption simplifies the calculation of the posterior probability, making the algorithm computationally efficient.
Working Steps of Naïve Bayes Algorithm:
- Calculate the prior probabilities of each class.
- For each attribute, calculate the likelihood of each value given each class.
- For a new data instance, calculate the posterior probability of each class using Bayes’ theorem.
- Assign the data instance to the class with the highest posterior probability.
Advantages of Naïve Bayes:
- Simple and easy to implement
- Computationally efficient
- Effective in many real-world applications, especially text classification
- Handles high-dimensional data well
Disadvantages of Naïve Bayes:
- The naïve independence assumption may not hold in all cases
- Sensitive to the presence of irrelevant attributes
- May suffer from the “zero-frequency” problem (if a value of an attribute is not seen in the training data, the likelihood will be zero)
2.3. Support Vector Machines (SVM)
Support Vector Machines (SVM) are a powerful and versatile classification technique. SVM aims to find the optimal hyperplane that separates data points of different classes with the largest margin. The margin is the distance between the hyperplane and the closest data points, known as support vectors.
2.3.1. Hyperplane
In SVM, a hyperplane is a decision boundary that separates data points of different classes. The optimal hyperplane is the one that maximizes the margin.
2.3.2. Support Vectors
Support vectors are the data points that lie closest to the hyperplane. These points are critical in determining the position and orientation of the hyperplane.
2.3.3. Kernel Functions
SVM can also learn non-linear decision functions by projecting the input data onto a high-dimensional feature space using kernel functions. Kernel functions allow SVM to operate in the original feature space without explicitly computing the coordinates of the data in the higher-dimensional space. Common kernel functions include:
- Linear Kernel
- Polynomial Kernel
- Radial Basis Function (RBF) Kernel
- Sigmoid Kernel
Working Steps of SVM Algorithm:
- Select a kernel function.
- Train the SVM model using the training data.
- Find the optimal hyperplane that maximizes the margin.
- Identify the support vectors.
- Use the hyperplane and support vectors to classify new data instances.
Advantages of SVM:
- Effective in high-dimensional spaces
- Versatile (different kernel functions can be used for different types of data)
- Memory efficient (uses a subset of training points in the decision function)
Disadvantages of SVM:
- Computationally expensive, especially for large datasets
- Difficult to choose an appropriate kernel function
- Not easily interpretable
2.4. K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) is a simple and intuitive classification algorithm. KNN classifies a new data instance based on the majority class of its k nearest neighbors in the training data. The value of k is a parameter that needs to be chosen carefully.
2.4.1. Distance Metrics
KNN relies on distance metrics to determine the nearest neighbors. Common distance metrics include:
- Euclidean Distance
- Manhattan Distance
- Minkowski Distance
Working Steps of KNN Algorithm:
- Choose the value of k.
- Calculate the distance between the new data instance and all data points in the training data.
- Select the k nearest neighbors based on the distance metric.
- Assign the new data instance to the majority class of the k nearest neighbors.
Advantages of KNN:
- Simple and easy to implement
- No training phase required (lazy learning)
- Versatile (can be used for classification and regression)
Disadvantages of KNN:
- Computationally expensive, especially for large datasets
- Sensitive to the choice of k
- Sensitive to irrelevant attributes
- Requires a suitable distance metric
2.5. Artificial Neural Networks (ANN)
Artificial Neural Networks (ANN) are a powerful classification technique inspired by the structure and function of biological neural networks. ANNs consist of interconnected nodes (neurons) organized in layers. Each connection between neurons has a weight associated with it. ANNs learn by adjusting these weights based on the training data.
2.5.1. Architecture
A typical ANN consists of three types of layers:
- Input Layer: Receives the input data.
- Hidden Layer(s): Performs the main processing.
- Output Layer: Produces the final output.
2.5.2. Training
ANNs are trained using algorithms such as backpropagation. Backpropagation involves adjusting the weights of the connections between neurons to minimize the difference between the predicted output and the actual output.
Working Steps of ANN Algorithm:
- Initialize the weights of the connections between neurons.
- Feed the input data through the network.
- Calculate the output of the network.
- Calculate the error between the predicted output and the actual output.
- Adjust the weights of the connections between neurons using backpropagation.
- Repeat steps 2-5 until the error is minimized.
Advantages of ANN:
- Capable of modeling complex relationships
- Robust to noise and missing data
- Can handle large amounts of data
Disadvantages of ANN:
- Computationally expensive
- Difficult to interpret
- Requires careful selection of the network architecture and training parameters
3. Comparative Analysis of Classification Techniques
To effectively use classification techniques in data mining, it is essential to understand their comparative strengths and weaknesses. This section provides a comparative analysis of the key classification algorithms discussed above.
3.1. Accuracy
Accuracy is a key metric for evaluating the performance of classification algorithms. It measures the proportion of correctly classified instances.
- SVM and ANN: Generally provide high accuracy, especially for complex datasets.
- Decision Trees: Can achieve good accuracy but are prone to overfitting.
- Naïve Bayes: Can be surprisingly accurate, especially for text classification.
- KNN: Accuracy depends on the choice of k and the distance metric.
3.2. Computational Complexity
Computational complexity refers to the amount of time and resources required to train and use a classification algorithm.
- Naïve Bayes: Computationally efficient.
- Decision Trees: Relatively fast to train and use.
- KNN: Computationally expensive, especially for large datasets.
- SVM and ANN: Computationally expensive, especially for training.
3.3. Interpretability
Interpretability refers to the ease with which the classification model can be understood and explained.
- Decision Trees: Highly interpretable.
- Naïve Bayes: Relatively interpretable.
- KNN: Interpretable to some extent (can examine the nearest neighbors).
- SVM and ANN: Difficult to interpret (black box models).
3.4. Handling of Data Types
Different classification algorithms are suitable for different types of data.
- Decision Trees and C4.5: Can handle both categorical and numerical data.
- Naïve Bayes: Typically used for categorical data but can be adapted for numerical data.
- KNN: Can handle both categorical and numerical data (requires a suitable distance metric for categorical data).
- SVM and ANN: Can handle both categorical and numerical data (numerical data may need to be scaled).
3.5. Robustness to Noise and Missing Data
Robustness refers to the ability of a classification algorithm to maintain its performance in the presence of noise and missing data.
- ANN: Robust to noise and missing data.
- SVM: Relatively robust to noise.
- Decision Trees: Can handle missing data but are sensitive to noise.
- Naïve Bayes: Sensitive to irrelevant attributes and the “zero-frequency” problem.
- KNN: Sensitive to irrelevant attributes.
4. Practical Applications of Classification Techniques
Classification techniques are used in a wide range of applications across various industries. Here are some practical examples:
- Medical Diagnosis: Classifying patients as having a disease or not based on symptoms and test results.
- Financial Analysis: Assessing credit risk, detecting fraud, and predicting stock prices.
- Marketing: Segmenting customers, predicting customer churn, and recommending products.
- Spam Detection: Classifying emails as spam or not spam.
- Image Recognition: Identifying objects in images and videos.
- Natural Language Processing: Sentiment analysis, text classification, and language detection.
5. Steps to Implement Classification Techniques
Implementing classification techniques in data mining involves several key steps. Here is a general outline of the process:
- Data Collection: Gather the data needed for the classification task.
- Data Preprocessing: Clean, transform, and prepare the data for analysis.
- Feature Selection: Choose the most relevant attributes for classification.
- Algorithm Selection: Select the most appropriate classification algorithm for the task.
- Model Training: Train the classification model using the training data.
- Model Evaluation: Evaluate the performance of the model using the test data.
- Model Deployment: Deploy the model for use in real-world applications.
5.1. Data Collection
The first step in implementing classification techniques is to collect the data needed for the classification task. The data should be relevant to the problem and of sufficient quality. Data sources can include databases, spreadsheets, text files, web APIs, and sensors.
5.2. Data Preprocessing
Data preprocessing involves cleaning, transforming, and preparing the data for analysis. This may include:
- Data Cleaning: Handling missing values, removing duplicates, and correcting errors.
- Data Transformation: Scaling numerical data, encoding categorical data, and creating new features.
- Data Reduction: Reducing the dimensionality of the data by selecting a subset of the most relevant attributes.
5.3. Feature Selection
Feature selection involves choosing the most relevant attributes for classification. This can improve the accuracy and efficiency of the classification model. Feature selection techniques include:
- Filter Methods: Select features based on statistical measures such as correlation and information gain.
- Wrapper Methods: Evaluate subsets of features by training and testing a classification model.
- Embedded Methods: Perform feature selection as part of the model training process.
5.4. Algorithm Selection
Selecting the most appropriate classification algorithm for the task is a critical step. Consider the characteristics of the data, the goals of the analysis, and the strengths and weaknesses of the different algorithms.
5.5. Model Training
Model training involves using the training data to build the classification model. The training data should be representative of the population and of sufficient size to avoid overfitting.
5.6. Model Evaluation
Model evaluation involves evaluating the performance of the model using the test data. This can be done using metrics such as accuracy, precision, recall, F1-score, and AUC.
5.7. Model Deployment
Model deployment involves deploying the model for use in real-world applications. This may involve integrating the model into a software system, creating a web service, or using the model to make predictions in real-time.
6. Tips for Optimizing Classification Performance
Optimizing the performance of classification models is essential for achieving the best possible results. Here are some tips for optimizing classification performance:
- Data Quality: Ensure the data is clean, accurate, and relevant.
- Feature Engineering: Create new features that capture important information.
- Algorithm Selection: Choose the most appropriate algorithm for the task.
- Hyperparameter Tuning: Optimize the hyperparameters of the algorithm using techniques such as grid search and cross-validation.
- Ensemble Methods: Combine multiple classification models to improve performance.
- Regularization: Use regularization techniques to prevent overfitting.
- Cross-Validation: Use cross-validation to evaluate the performance of the model and prevent overfitting.
7. Challenges and Future Trends
While classification techniques have made significant advances, there are still several challenges to address. Some of the key challenges and future trends include:
- Handling Imbalanced Data: Developing techniques for handling datasets with imbalanced class distributions.
- Dealing with High-Dimensional Data: Developing techniques for dealing with datasets with a large number of attributes.
- Improving Interpretability: Developing more interpretable classification models.
- Integrating Deep Learning: Integrating deep learning techniques into classification models.
- Automated Machine Learning (AutoML): Developing automated tools for selecting and optimizing classification models.
- Explainable AI (XAI): Developing methods for explaining the decisions made by classification models.
8. The Role of COMPARE.EDU.VN
COMPARE.EDU.VN provides valuable resources for understanding and comparing classification techniques in data mining. Whether you’re comparing machine learning techniques, statistical methods, or specific algorithms, our platform offers detailed analyses and objective comparisons to guide your decision-making.
8.1. How COMPARE.EDU.VN Helps
COMPARE.EDU.VN offers:
- Detailed Comparisons: Side-by-side comparisons of different classification algorithms, including their strengths, weaknesses, and use cases.
- Expert Reviews: Reviews and analyses from data mining experts to help you understand the nuances of each technique.
- User Feedback: Insights from users who have implemented these techniques in real-world projects.
- Comprehensive Guides: Step-by-step guides on how to implement and optimize classification models.
8.2. Making Informed Decisions
By using COMPARE.EDU.VN, you can make informed decisions about which classification techniques to use in your data mining projects. Our platform helps you understand the tradeoffs between different algorithms, ensuring you select the best approach for your specific needs.
9. Conclusion
A comparative study of classification techniques in data mining algorithms is crucial for selecting the most appropriate method for a specific task. Understanding the strengths, weaknesses, and practical applications of different algorithms enables businesses and organizations to make informed decisions and achieve their data mining goals. By leveraging resources like COMPARE.EDU.VN, you can gain a deeper understanding of classification techniques and optimize your data analysis efforts.
Data mining and machine learning continue to evolve, offering increasingly sophisticated methods for data classification. Embrace these advancements to drive innovation and gain a competitive edge in your industry. For more in-depth comparisons and detailed reviews, visit COMPARE.EDU.VN at 333 Comparison Plaza, Choice City, CA 90210, United States, or contact us via Whatsapp at +1 (626) 555-9090. Let COMPARE.EDU.VN be your guide in navigating the complex world of data mining and classification.
Ready to make smarter decisions? Visit COMPARE.EDU.VN today to explore detailed comparisons and reviews of classification techniques in data mining algorithms. Don’t wait, unlock the power of informed decision-making now!
10. FAQ
10.1. What are the main types of classification techniques in data mining?
The main types include Decision Trees, Naïve Bayes, Support Vector Machines (SVM), K-Nearest Neighbors (KNN), and Artificial Neural Networks (ANN). Each has its strengths and is suited for different data types and problem complexities.
10.2. How do I choose the right classification algorithm for my data?
Consider the data type, size, and the problem you’re trying to solve. Decision Trees are interpretable, Naïve Bayes is efficient, SVM is effective in high-dimensional spaces, KNN is simple, and ANN is capable of modeling complex relationships. COMPARE.EDU.VN offers detailed comparisons to help you decide.
10.3. What is the advantage of using Decision Trees for classification?
Decision Trees are easy to understand and interpret, making them valuable for explaining the decision-making process. They can handle both categorical and numerical data with minimal preprocessing.
10.4. When is Naïve Bayes a good choice for classification?
Naïve Bayes is a good choice for text classification and spam filtering due to its simplicity and efficiency. It performs well with high-dimensional data, assuming feature independence.
10.5. What are Support Vector Machines (SVM) best suited for?
SVMs are best suited for high-dimensional spaces and complex classification tasks. They are effective in finding optimal hyperplanes to separate data classes, especially when using kernel functions for non-linear data.
10.6. How does the K-Nearest Neighbors (KNN) algorithm work?
KNN classifies new data points based on the majority class of its k nearest neighbors. It’s simple and versatile but can be computationally expensive for large datasets.
10.7. What makes Artificial Neural Networks (ANN) powerful for classification?
ANNs can model complex relationships and are robust to noise and missing data. They are suitable for large datasets but require significant computational resources and are difficult to interpret.
10.8. What is the role of data preprocessing in classification?
Data preprocessing ensures data is clean, accurate, and relevant. It involves handling missing values, scaling numerical data, and encoding categorical data, improving the accuracy and efficiency of classification models.
10.9. How can COMPARE.EDU.VN help in selecting classification techniques?
compare.edu.vn provides detailed comparisons, expert reviews, and user feedback to help you understand the strengths and weaknesses of different classification techniques. This enables informed decisions tailored to your specific needs.
10.10. What are some challenges in implementing classification techniques?
Challenges include handling imbalanced data, dealing with high-dimensional data, improving interpretability, and integrating advanced techniques like deep learning. Future trends focus on automated machine learning (AutoML) and explainable AI (XAI).