The age-old quest for faster sorting algorithms continues. While it’s widely known that comparison-based sorting algorithms have a lower bound of O(n log n) time complexity, can we achieve linear time, O(n), with a comparative sort? The short answer is no, but let’s delve into why and explore alternatives.
The Limits of Comparison-Based Sorting
Comparison-based sorting algorithms, like quicksort, merge sort, and heapsort, rely solely on comparing pairs of elements to determine their order. This fundamental reliance on comparisons introduces a constraint. To understand why, consider the decision tree model:
Each comparison in a sorting algorithm represents a decision point, branching the possible orderings of the input. For a list of ‘n’ elements, there are ‘n!’ (n factorial) possible permutations. A correct sorting algorithm must be able to distinguish between all of them.
The decision tree must have at least ‘n!’ leaves to represent each possible outcome. Since a binary tree of height ‘h’ has at most 2^h leaves, we have:
2^h >= n!Taking the logarithm base 2 of both sides:
h >= log2(n!)Using Stirling’s approximation for log2(n!), we get:
h >= n log2(n) - n log2(e) + O(log2(n))This demonstrates that the height of the decision tree, and therefore the minimum number of comparisons required, is proportional to n log n. Consequently, any comparison-based sorting algorithm has a lower bound of Ω(n log n).
Breaking the Barrier: Non-Comparison-Based Sorting
To achieve linear time complexity, we must venture beyond comparison-based sorting. Algorithms like counting sort, radix sort, and bucket sort exploit specific properties of the input data to circumvent the comparison limitation.
Radix sort, for example, distributes elements into buckets based on individual digits or groups of bits. By processing each digit position iteratively, radix sort can achieve O(nk) time complexity, where ‘k’ is the number of digits (or passes). If ‘k’ is constant or significantly smaller than ‘log n’, radix sort effectively performs in linear time.
Ska Sort: A Modern Take on Radix Sort
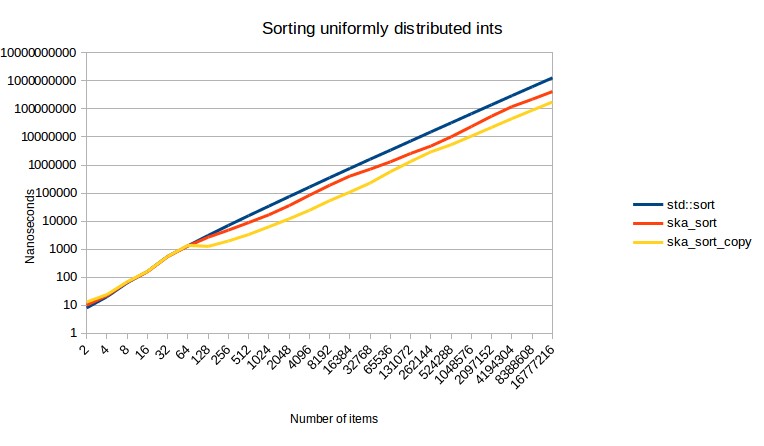
Ska Sort, a modern in-place radix sort implementation, demonstrates the potential of non-comparison-based sorting. It leverages optimized inner loops, recursion management, and fallback mechanisms to consistently outperform comparison-based algorithms like std::sort in many scenarios.
Ska Sort utilizes techniques like:
- Byte-wise Sorting: Processes data one byte at a time.
- Adaptive Fallbacks: Utilizes
std::sortor American Flag Sort for smaller datasets where those algorithms are more efficient. - Recursion Control: Limits recursion depth to avoid worst-case scenarios.
- Specialized Handling: Optimizes for various data types, including integers, floats, strings, and tuples.
Conclusion
While a comparative sorting algorithm cannot achieve linear time complexity due to the inherent limitations of comparison-based sorting, non-comparison-based algorithms like radix sort offer a viable path to O(n) performance under specific conditions. Modern implementations like Ska Sort highlight the practical advantages of these techniques, offering significant performance improvements over traditional comparison-based approaches. If performance is critical, exploring and utilizing non-comparison-based sorting algorithms is highly recommended.