Comparing standard deviations is a common practice, but can it be truly meaningful? COMPARE.EDU.VN delves into the nuances of comparing standard deviations, exploring the conditions under which comparisons are valid and the potential pitfalls to avoid. Discover a robust and reliable approach to data analysis. Understand the importance of context, data distribution, and alternative measures when analyzing variability with COMPARE.EDU.VN.
1. Understanding Standard Deviation
Standard deviation is a fundamental statistical measure that quantifies the amount of dispersion or variability within a set of data values. It reveals how much individual data points deviate from the average (mean) of the dataset. A low standard deviation signals that the data points are clustered closely around the mean, indicating less variability. Conversely, a high standard deviation suggests that the data points are more spread out, implying greater variability. Standard deviation is calculated as the square root of the variance, providing a readily interpretable value in the original units of measurement.
1.1. Definition and Calculation
Standard deviation, often denoted by the symbol σ (sigma) for a population or s for a sample, provides a single number that summarizes the spread of a dataset. To calculate the standard deviation, one must first compute the variance, which is the average of the squared differences from the mean.
Formula for Population Standard Deviation (σ):
σ = √[ Σ (xi – μ)² / N ]
Where:
- xi represents each individual data point in the population.
- μ is the population mean.
- N is the total number of data points in the population.
- Σ denotes the sum of the values.
Formula for Sample Standard Deviation (s):
s = √[ Σ (xi – x̄)² / (n – 1) ]
Where:
- xi represents each individual data point in the sample.
- x̄ is the sample mean.
- n is the total number of data points in the sample.
- Σ denotes the sum of the values.
The sample standard deviation uses (n-1) in the denominator to provide an unbiased estimate of the population standard deviation, especially when dealing with smaller sample sizes.
1.2. Interpreting Standard Deviation
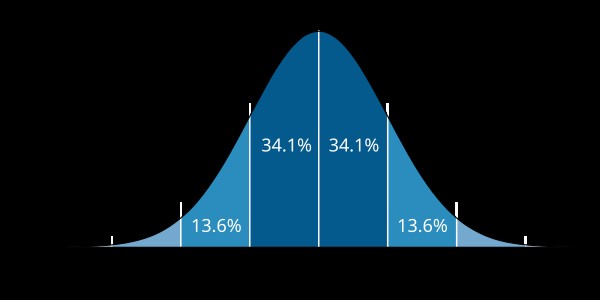
Interpreting standard deviation involves understanding its relationship to the mean and the distribution of the data. In a normal distribution, approximately 68% of the data falls within one standard deviation of the mean, 95% within two standard deviations, and 99.7% within three standard deviations. This is known as the 68-95-99.7 rule or the empirical rule.
For example, if the average height of adult males is 5’10” (70 inches) with a standard deviation of 3 inches, this means:
- About 68% of adult males have a height between 67 inches and 73 inches (5’7″ to 6’1″).
- About 95% of adult males have a height between 64 inches and 76 inches (5’4″ to 6’4″).
- About 99.7% of adult males have a height between 61 inches and 79 inches (5’1″ to 6’7″).
A larger standard deviation implies greater heterogeneity in the data, while a smaller standard deviation suggests more homogeneity.
1.3. Importance in Statistical Analysis
Standard deviation plays a crucial role in various statistical analyses:
- Hypothesis Testing: Standard deviation is essential for calculating test statistics such as t-tests and z-tests, which are used to determine the statistical significance of differences between means.
- Confidence Intervals: It is used to construct confidence intervals, providing a range within which the true population parameter is likely to fall.
- Quality Control: In manufacturing and other industries, standard deviation helps monitor process variability and ensure product consistency.
- Risk Management: In finance, standard deviation is used as a measure of volatility or risk associated with an investment.
- Data Comparison: Standard deviation allows for the comparison of variability between different datasets, provided certain conditions are met, as discussed in the following sections.
Understanding and correctly interpreting standard deviation is vital for making informed decisions based on data.
2. Conditions for Meaningful Comparison
Comparing standard deviations directly can be misleading without considering certain crucial conditions. The validity of such comparisons hinges on the nature of the data, the context in which it was collected, and the statistical assumptions underlying the analysis. Failure to account for these conditions can lead to incorrect conclusions and flawed decision-making.
2.1. Same Units of Measurement
For a meaningful comparison, the standard deviations must be calculated from datasets measured in the same units. Comparing the standard deviation of heights measured in inches to the standard deviation of weights measured in pounds, for example, is nonsensical. The units are different, and thus, the scales of variability are not directly comparable.
If the units of measurement differ, consider converting the data to a common scale or using dimensionless measures of variability, such as the coefficient of variation, which will be discussed later.
2.2. Similar Means
When comparing standard deviations, it’s important to consider whether the means of the datasets are similar. If the means are drastically different, a larger standard deviation might simply reflect a higher overall scale of values rather than greater relative variability.
For example, consider two sets of test scores:
- Set A: Mean = 60, Standard Deviation = 10
- Set B: Mean = 90, Standard Deviation = 10
Although both datasets have the same standard deviation, the variability relative to their means is different. In Set A, a standard deviation of 10 represents a larger proportion of the mean compared to Set B. The coefficient of variation can help address this issue.
2.3. Similar Distributions
The shape of the data distribution significantly impacts the interpretability of the standard deviation. Standard deviation is most meaningful when the data is approximately normally distributed. If the distributions are highly skewed or have significant outliers, the standard deviation might not accurately represent the typical spread of the data.
Consider these scenarios:
- Normally Distributed Data: Standard deviation provides a clear and reliable measure of variability.
- Skewed Data: Standard deviation can be misleading because it is influenced by extreme values in the tail of the distribution. In such cases, alternative measures like the interquartile range (IQR) might be more appropriate.
- Data with Outliers: Outliers can inflate the standard deviation, making it seem like there is more variability than truly exists in the bulk of the data. Robust measures of variability, less sensitive to outliers, should be considered.
2.4. Independence of Data Points
The standard deviation calculation assumes that the data points are independent of each other. If the data points are correlated, the standard deviation may underestimate the true variability.
For example, if you are measuring the blood pressure of a patient multiple times throughout the day, these measurements are likely to be correlated. The standard deviation calculated from these measurements might not accurately reflect the overall variability in blood pressure if the correlation is not taken into account. Time series analysis or other methods that account for autocorrelation should be used in such cases.
Understanding these conditions is crucial for making valid comparisons of standard deviations. When these conditions are not met, alternative measures of variability or transformations of the data might be necessary to draw meaningful conclusions. If you need help comparing sets of data, turn to COMPARE.EDU.VN for a comprehensive evaluation. Contact us at 333 Comparison Plaza, Choice City, CA 90210, United States or Whatsapp at +1 (626) 555-9090.
3. Alternative Measures of Variability
When the conditions for comparing standard deviations are not met, or when a more nuanced understanding of variability is required, alternative measures can provide valuable insights. These measures offer different perspectives on data dispersion and are often more robust to outliers or variations in data distribution.
3.1. Coefficient of Variation (CV)
The coefficient of variation (CV) is a dimensionless measure of relative variability. It is calculated as the ratio of the standard deviation to the mean, expressed as a percentage:
CV = (Standard Deviation / Mean) * 100%
The CV is particularly useful when comparing the variability of datasets with different means or different units of measurement. By standardizing the standard deviation relative to the mean, the CV allows for a direct comparison of relative dispersion.
For example, consider two investment portfolios:
- Portfolio A: Mean Return = 5%, Standard Deviation = 2%
- Portfolio B: Mean Return = 10%, Standard Deviation = 3%
Comparing the standard deviations directly might suggest that Portfolio B is more volatile. However, calculating the CV provides a different perspective:
- CV for Portfolio A: (2% / 5%) * 100% = 40%
- CV for Portfolio B: (3% / 10%) * 100% = 30%
The CV shows that Portfolio A has a higher relative variability compared to Portfolio B, despite having a lower standard deviation.
3.2. Interquartile Range (IQR)
The interquartile range (IQR) is a measure of statistical dispersion equal to the difference between the 75th percentile (Q3) and the 25th percentile (Q1) of the data. It represents the range of the middle 50% of the data and is less sensitive to extreme values or outliers compared to the standard deviation.
IQR = Q3 – Q1
The IQR is particularly useful for skewed distributions or datasets with outliers, where the standard deviation might be misleading. It provides a more robust measure of the typical spread of the data.
For example, consider a dataset of salaries with a few very high earners:
- Q1 = $40,000
- Q3 = $60,000
The IQR is $60,000 – $40,000 = $20,000, indicating that the middle 50% of salaries fall within a range of $20,000. This measure is not affected by the extreme high salaries, providing a more accurate representation of the salary dispersion for the majority of employees.
3.3. Median Absolute Deviation (MAD)
The median absolute deviation (MAD) is another robust measure of variability that is less sensitive to outliers. It is calculated as the median of the absolute deviations from the data’s median:
MAD = median(|xi – median(x)|)
Where:
- xi represents each individual data point.
- median(x) is the median of the dataset.
The MAD provides a measure of the typical deviation from the median, without being unduly influenced by extreme values.
For example, consider a dataset of response times with a few unusually long response times:
1, 2, 2, 3, 4, 10
- Median = 2.5
- Absolute Deviations from Median: 1.5, 0.5, 0.5, 0.5, 1.5, 7.5
- MAD = median(1.5, 0.5, 0.5, 0.5, 1.5, 7.5) = 1.0
The MAD is 1.0, indicating that the typical deviation from the median response time is 1 unit. This measure is not greatly affected by the outlier of 10, providing a more stable measure of variability.
3.4. Range
The range is the simplest measure of variability, calculated as the difference between the maximum and minimum values in the dataset:
Range = Maximum Value – Minimum Value
While easy to calculate, the range is highly sensitive to outliers and may not accurately represent the variability of the entire dataset. It is best used in situations where a quick, rough estimate of dispersion is needed, and outliers are not a major concern.
3.5. Variance
Variance, denoted by σ² for a population or s² for a sample, is the average of the squared differences from the mean. It is the square of the standard deviation and provides a measure of the overall spread of the data. While variance is not in the same units as the original data (e.g., if the data is in meters, the variance is in square meters), it is a fundamental component in many statistical analyses.
3.6. Choosing the Right Measure
The choice of which variability measure to use depends on the specific characteristics of the data and the goals of the analysis:
- Standard Deviation: Best for normally distributed data without significant outliers.
- Coefficient of Variation: Useful for comparing datasets with different means or units.
- IQR: Robust measure for skewed data or datasets with outliers.
- MAD: Another robust measure, particularly useful when the median is a more appropriate measure of central tendency than the mean.
- Range: Quick, rough estimate of dispersion, but sensitive to outliers.
- Variance: A fundamental measure used in many statistical calculations, but not directly interpretable in the original units.
By understanding the strengths and limitations of these alternative measures, analysts can gain a more comprehensive and accurate understanding of data variability, leading to better-informed decisions. COMPARE.EDU.VN has the experience to guide you through these decisions, offering a clearer understanding of variability.
4. Practical Examples
To illustrate the concepts discussed, let’s consider several practical examples where comparing standard deviations or using alternative measures of variability is essential.
4.1. Comparing Test Scores
Suppose we have two classes of students who took the same test. The scores are as follows:
- Class A: Mean = 75, Standard Deviation = 10
- Class B: Mean = 85, Standard Deviation = 12
At first glance, it might seem that Class B has more variability because its standard deviation is higher. However, we should also consider the means. Class B has a higher average score, so a larger standard deviation might be expected. To make a fair comparison, we can calculate the coefficient of variation (CV):
- CV for Class A: (10 / 75) * 100% = 13.33%
- CV for Class B: (12 / 85) * 100% = 14.12%
The CVs are quite similar, suggesting that the relative variability in both classes is comparable. In this case, directly comparing the standard deviations would have been misleading without considering the difference in means.
4.2. Analyzing Product Quality
A manufacturing company produces bolts, and two machines are used to produce them. The company wants to compare the consistency of the bolt lengths produced by each machine. The data (in millimeters) is as follows:
- Machine 1: 25.1, 25.2, 24.9, 25.0, 25.3
- Machine 2: 24.0, 26.0, 25.5, 24.5, 25.0
Calculating the standard deviations:
- Standard Deviation for Machine 1: 0.158 mm
- Standard Deviation for Machine 2: 0.837 mm
Machine 2 has a much higher standard deviation, indicating that the bolt lengths produced by Machine 2 are more variable. This information can help the company identify that Machine 2 may need maintenance or recalibration to improve consistency.
4.3. Financial Portfolio Risk Assessment
An investor wants to compare the risk associated with two different investment portfolios. The annual returns over the past 10 years are:
- Portfolio A: 8%, 10%, 6%, 12%, 9%, 7%, 11%, 5%, 10%, 8%
- Portfolio B: 2%, 15%, -5%, 20%, 5%, -2%, 18%, -8%, 12%, 3%
Calculating the standard deviations:
- Standard Deviation for Portfolio A: 2.05%
- Standard Deviation for Portfolio B: 9.75%
Portfolio B has a much higher standard deviation, indicating that it is more volatile and, therefore, riskier than Portfolio A. However, it’s also important to consider the potential for higher returns with Portfolio B, as indicated by the higher returns. The investor can use this information to make an informed decision based on their risk tolerance.
4.4. Comparing Reaction Times
In a psychological experiment, researchers measure the reaction times of participants under two different conditions. The data (in milliseconds) is as follows:
- Condition X: 250, 260, 245, 255, 270, 265, 258, 240, 252, 263
- Condition Y: 280, 290, 275, 285, 300, 295, 288, 270, 282, 293
Calculating the standard deviations:
- Standard Deviation for Condition X: 9.57 ms
- Standard Deviation for Condition Y: 9.57 ms
Both conditions have the same standard deviation. However, the means are different:
- Mean for Condition X: 255.8 ms
- Mean for Condition Y: 285.8 ms
The equal standard deviations indicate that the spread of reaction times is similar in both conditions, but the reaction times are generally slower under Condition Y. This suggests that Condition Y introduces a consistent delay in reaction times, without affecting the variability.
4.5. Assessing Manufacturing Tolerances
A manufacturing company produces components that must meet specific tolerances. The target dimension is 50 mm, with a tolerance of ±0.5 mm. Two production lines are evaluated:
- Line 1: Measurements are tightly clustered around 50 mm.
- Line 2: Measurements are more spread out, with some values close to the tolerance limits.
In this scenario, the standard deviation is a critical metric for assessing whether the production lines are meeting the required tolerances. A higher standard deviation in Line 2 indicates that the components produced by this line are more likely to fall outside the acceptable tolerance range, leading to potential quality issues.
4.6. Evaluating Student Performance
An educator wants to evaluate the performance of students across different subjects. The average scores and standard deviations for two subjects are:
- Math: Mean = 78, Standard Deviation = 8
- English: Mean = 82, Standard Deviation = 10
While English has a higher standard deviation, the mean score is also higher. To determine which subject has more relative variability, the coefficient of variation (CV) is calculated:
- CV for Math: (8 / 78) * 100% = 10.26%
- CV for English: (10 / 82) * 100% = 12.20%
The CV indicates that the relative variability in English scores is higher compared to Math scores. This suggests that there is more variation in student performance in English, which could prompt the educator to investigate the factors contributing to this variability.
Through these practical examples, it becomes evident that the appropriate interpretation and comparison of standard deviations, along with the consideration of alternative measures, are essential for drawing accurate conclusions and making informed decisions in various fields. Don’t try to make these comparisons on your own. Instead, visit COMPARE.EDU.VN to examine the facts!
5. Common Pitfalls to Avoid
When comparing standard deviations, it’s crucial to be aware of common pitfalls that can lead to misinterpretations and incorrect conclusions. Avoiding these mistakes ensures a more accurate and reliable analysis.
5.1. Ignoring the Context of the Data
One of the most common mistakes is comparing standard deviations without considering the context of the data. The meaning of a standard deviation is always relative to the specific situation and the nature of the data being analyzed.
For example, a standard deviation of 5 in a dataset of exam scores (out of 100) might indicate reasonable variability. However, a standard deviation of 5 in a dataset of temperature measurements (in degrees Celsius) might be significant if the typical temperature range is narrow.
Always consider the following:
- Units of Measurement: Ensure the units are the same when comparing standard deviations.
- Nature of the Variable: Understand the characteristics of the variable being measured (e.g., continuous, discrete, categorical).
- Expected Range: Know the typical range of values for the variable to assess the significance of the standard deviation.
5.2. Comparing Standard Deviations from Different Populations
Comparing standard deviations from different populations can be misleading if the populations have inherently different characteristics.
For example, comparing the standard deviation of heights of adult males to the standard deviation of heights of adult females without accounting for the known height differences between the sexes is problematic. The populations are different, and a direct comparison of standard deviations might not provide meaningful insights.
In such cases, it’s important to:
- Stratify the Data: Analyze the data separately for each population subgroup.
- Consider Population-Specific Norms: Compare the standard deviations to population-specific benchmarks or norms.
5.3. Neglecting the Shape of the Distribution
The standard deviation is most informative when the data is approximately normally distributed. If the distribution is highly skewed or has significant outliers, the standard deviation might not accurately represent the typical spread of the data.
- Skewed Distributions: In skewed distributions, the standard deviation can be influenced by extreme values in the tail of the distribution. Alternative measures like the interquartile range (IQR) might be more appropriate.
- Outliers: Outliers can inflate the standard deviation, making it seem like there is more variability than truly exists in the bulk of the data. Robust measures of variability, less sensitive to outliers, should be considered.
5.4. Assuming Equal Sample Sizes
When comparing standard deviations from samples, it’s important to consider the sample sizes. Standard deviations calculated from small samples are more susceptible to sampling error and might not accurately represent the population variability.
- Small Sample Sizes: Use caution when interpreting standard deviations from small samples. Consider using confidence intervals to provide a range of plausible values for the population standard deviation.
- Unequal Sample Sizes: When comparing standard deviations from samples with unequal sizes, statistical tests such as the F-test for equality of variances should be used to determine if the differences are statistically significant.
5.5. Ignoring Statistical Significance
Even if two standard deviations appear different, the difference might not be statistically significant. Statistical significance refers to the likelihood that the observed difference is not due to random chance.
- Hypothesis Testing: Use statistical tests, such as the F-test or Levene’s test, to formally test whether the variances (and therefore the standard deviations) of two groups are significantly different.
- P-value: Interpret the p-value associated with the test. A low p-value (typically less than 0.05) indicates that the difference is statistically significant.
5.6. Over-reliance on Standard Deviation Alone
Standard deviation is a valuable measure of variability, but it should not be the only metric considered. Over-reliance on standard deviation without considering other factors can lead to an incomplete or misleading analysis.
- Consider Central Tendency: Always consider the mean or median along with the standard deviation to understand both the average value and the spread of the data.
- Visualize the Data: Use histograms, box plots, or other graphical methods to visualize the distribution of the data and identify potential issues such as skewness or outliers.
- Use Multiple Measures: Consider using multiple measures of variability, such as the IQR or MAD, to provide a more comprehensive understanding of data dispersion.
By being aware of these common pitfalls and taking steps to avoid them, analysts can ensure that their comparisons of standard deviations are accurate, reliable, and meaningful. For an easy way to compare data, turn to the pros at COMPARE.EDU.VN!
6. Statistical Tests for Comparing Variances
When comparing the variability of two or more groups, statistical tests are essential for determining whether the observed differences are statistically significant. These tests provide a formal way to assess whether the variances (and therefore the standard deviations) of the groups are different enough to conclude that they come from different populations.
6.1. F-Test for Equality of Variances
The F-test is a statistical test used to compare the variances of two populations. It is based on the F-distribution and is particularly sensitive to departures from normality.
Assumptions:
- The data for each group is normally distributed.
- The data points are independent.
Hypotheses:
- Null Hypothesis (H0): The variances of the two populations are equal (σ1² = σ2²).
- Alternative Hypothesis (H1): The variances of the two populations are not equal (σ1² ≠ σ2²).
Test Statistic:
The F-statistic is calculated as the ratio of the two sample variances:
F = s1² / s2²
Where:
- s1² is the sample variance of group 1.
- s2² is the sample variance of group 2.
Procedure:
- Calculate the sample variances s1² and s2².
- Calculate the F-statistic.
- Determine the degrees of freedom for each group: df1 = n1 – 1 and df2 = n2 – 1, where n1 and n2 are the sample sizes.
- Find the p-value associated with the F-statistic using the F-distribution with df1 and df2 degrees of freedom.
- Compare the p-value to the significance level (α). If the p-value is less than α (typically 0.05), reject the null hypothesis and conclude that the variances are significantly different.
Example:
Suppose we want to compare the variances of test scores for two different schools:
- School A: n1 = 30, s1² = 100
- School B: n2 = 40, s2² = 144
- Calculate the F-statistic: F = 100 / 144 = 0.694
- Determine the degrees of freedom: df1 = 30 – 1 = 29 and df2 = 40 – 1 = 39
- Find the p-value using an F-distribution with 29 and 39 degrees of freedom. The p-value is approximately 0.24.
- Since the p-value (0.24) is greater than the significance level (0.05), we fail to reject the null hypothesis and conclude that there is no significant difference in the variances of the test scores between the two schools.
6.2. Levene’s Test for Equality of Variances
Levene’s test is a more robust alternative to the F-test, as it is less sensitive to departures from normality. It tests whether the variances of two or more groups are equal.
Assumptions:
- The data points are independent.
- The data does not need to be normally distributed.
Hypotheses:
- Null Hypothesis (H0): The variances of the groups are equal.
- Alternative Hypothesis (H1): The variances of the groups are not equal.
Test Statistic:
Levene’s test involves transforming the data and then performing an ANOVA on the transformed data. The test statistic is calculated based on the absolute deviations from the group means (or medians).
Procedure:
- Calculate the absolute deviations from the group means (or medians): zi,j = |xi,j – x̄j|, where xi,j is the jth observation in group i and x̄j is the mean (or median) of group j.
- Perform a one-way ANOVA on the absolute deviations zi,j.
- Obtain the F-statistic and the associated p-value from the ANOVA.
- Compare the p-value to the significance level (α). If the p-value is less than α (typically 0.05), reject the null hypothesis and conclude that the variances are significantly different.
Example:
Suppose we want to compare the variances of reaction times for three different experimental conditions. The data may not be normally distributed. We can use Levene’s test to assess whether the variances are equal.
Using statistical software, we perform Levene’s test and obtain the following results:
- F-statistic = 3.5
- p-value = 0.03
Since the p-value (0.03) is less than the significance level (0.05), we reject the null hypothesis and conclude that there is a significant difference in the variances of the reaction times among the three conditions.
6.3. Bartlett’s Test for Equality of Variances
Bartlett’s test is another statistical test used to compare the variances of two or more groups. It is more sensitive to departures from normality than Levene’s test but can be more powerful when the data is approximately normally distributed.
Assumptions:
- The data for each group is normally distributed.
- The data points are independent.
Hypotheses:
- Null Hypothesis (H0): The variances of the groups are equal.
- Alternative Hypothesis (H1): The variances of the groups are not equal.
Test Statistic:
Bartlett’s test statistic is calculated based on the sample variances and sample sizes of the groups.
Procedure:
- Calculate the sample variances si² for each group i.
- Calculate the pooled variance sp² = Σ(di * si²) / Σdi, where di = ni – 1 is the degrees of freedom for each group.
- Calculate the Bartlett’s test statistic: B = (Σdi) ln(sp²) – Σ(di ln(si²)).
- The test statistic B follows a chi-squared distribution with k – 1 degrees of freedom, where k is the number of groups.
- Find the p-value associated with the test statistic using the chi-squared distribution.
- Compare the p-value to the significance level (α). If the p-value is less than α (typically 0.05), reject the null hypothesis and conclude that the variances are significantly different.
6.4. Choosing the Right Test
The choice of which test to use depends on the characteristics of the data:
- F-Test: Use when the data is approximately normally distributed and you are comparing the variances of two groups.
- Levene’s Test: Use when the data may not be normally distributed, and you are comparing the variances of two or more groups.
- Bartlett’s Test: Use when the data is approximately normally distributed, and you are comparing the variances of two or more groups.
By using these statistical tests, analysts can make informed decisions about whether the observed differences in variability between groups are statistically significant, leading to more robust and reliable conclusions. If you aren’t sure which statistical test is right for your circumstances, COMPARE.EDU.VN can help!
7. Enhancing Data Analysis with COMPARE.EDU.VN
In the complex world of data analysis, having access to reliable, comprehensive, and user-friendly resources is essential. COMPARE.EDU.VN is dedicated to providing the tools and information needed to make informed decisions based on sound statistical principles. Here’s how COMPARE.EDU.VN enhances your data analysis efforts:
7.1. Comprehensive Comparisons
COMPARE.EDU.VN offers detailed comparisons of various statistical methods and tools, including measures of variability. Whether you’re trying to decide between using standard deviation, coefficient of variation, IQR, or other measures, our platform provides clear explanations and practical examples to guide your choice.
7.2. User-Friendly Interface
Navigating statistical concepts can be challenging, which is why COMPARE.EDU.VN is designed with a user-friendly interface. Our website is easy to navigate, allowing you to quickly find the information you need without getting bogged down in technical jargon.
7.3. Expert Insights
COMPARE.EDU.VN provides access to expert insights and analyses from experienced statisticians and data analysts. Our team is committed to delivering accurate, up-to-date information that you can trust. We break down complex topics into manageable segments, making it easier for you to understand and apply statistical concepts.
7.4. Practical Examples and Case Studies
To reinforce your understanding, COMPARE.EDU.VN offers numerous practical examples and case studies. These real-world applications demonstrate how to use different statistical measures and tests, helping you to see the practical implications of your data analysis.
7.5. Statistical Test Selection Tools
Choosing the right statistical test is crucial for drawing valid conclusions. COMPARE.EDU.VN provides interactive tools to help you select the appropriate test based on your data type, research question, and assumptions. These tools streamline the decision-making process and ensure that you’re using the most suitable method for your analysis.
7.6. Guidance on Interpretation
Interpreting statistical results can be tricky. COMPARE.EDU.VN offers clear guidance on how to interpret p-values, confidence intervals, and other statistical outputs. We help you understand what your results mean in the context of your research or analysis, enabling you to communicate your findings effectively.
7.7. Educational Resources
Whether you’re a student, researcher, or business professional, COMPARE.EDU.VN provides a wealth of educational resources to enhance your statistical knowledge. From introductory tutorials to advanced topics, our platform covers a wide range of subjects to support your learning journey.
7.8. Data Visualization Tools
Visualizing data is essential for identifying patterns, trends, and outliers. COMPARE.EDU.VN offers access to data visualization tools that allow you to create compelling charts and graphs. These visual aids help you to explore your data and communicate your findings in a clear and engaging manner.
7.9. Support and Assistance
If you need help with your data analysis, COMPARE.EDU.VN offers support and assistance. Our team is available to answer your questions and provide guidance on statistical methods and tools. We’re committed to helping you succeed in your data analysis endeavors.
7.10. Real-World Application
From comparing product quality in manufacturing to assessing financial portfolio risk, the principles discussed throughout this article have wide-ranging applications. By understanding how to properly compare standard deviations and utilize alternative measures of variability, professionals across various industries can make more informed decisions, improve processes, and drive success.
7.11. The COMPARE.EDU.VN Advantage
With COMPARE.EDU.VN, you gain a partner in your data analysis journey. We empower you to make better decisions, uncover valuable insights, and achieve your goals. Our platform is designed to be your go-to resource for all things statistical, providing you with the knowledge and tools you need to succeed.
By leveraging the resources available at COMPARE.EDU.VN, you can elevate your data analysis skills and gain a competitive edge in your field. Whether you’re comparing test scores, analyzing product quality, assessing financial risk, or evaluating reaction times, our platform provides the support you need to make informed decisions based on solid statistical principles.
8. Conclusion
Comparing standard deviations can be a valuable tool for understanding and interpreting data variability, but it must be done with careful consideration of the underlying assumptions and context. While a direct comparison might seem straightforward, several conditions must be met to ensure the comparison is meaningful and accurate. Factors such as the same units of measurement, similar means, similar distributions, and independence of data points play crucial roles in determining the validity of such comparisons.
When these conditions are not met, relying solely on standard deviations can lead to misinterpretations and flawed decision-making. In such cases, alternative measures of variability, such as the coefficient of variation (CV), interquartile range (IQR), median absolute deviation (MAD), and range, offer more robust and informative insights. These measures provide different perspectives on data dispersion and are often less sensitive to outliers or variations in data distribution.
Statistical tests, such as the F-test, Levene’s test, and Bartlett’s test, are essential for formally assessing whether the observed differences in variability between groups are statistically significant. These tests help determine if the variances (and therefore the standard deviations) of the groups are different enough to conclude that they come from different populations.
By understanding the nuances of comparing standard deviations and utilizing alternative measures and statistical tests when appropriate, analysts can gain a more comprehensive and accurate understanding of data variability. This leads to better-informed decisions, improved processes, and greater success in various fields, from education and manufacturing to finance and psychology.
To further enhance your data analysis skills and make informed decisions based on sound statistical principles, visit compare.edu.vn.