A comparative study on reasoning patterns of OpenAI’s O1 model unveils its unique approach to problem-solving across diverse domains. COMPARE.EDU.VN offers a detailed analysis, providing insights into how O1 handles mathematical, coding, and commonsense reasoning tasks, ensuring you can make informed decisions about AI model applications. Explore the nuances of AI reasoning, comparing methodologies and gaining valuable insights into cognitive processing, enhancing your understanding of algorithmic efficiency.
1. Introduction to OpenAI’s O1 Model Reasoning Patterns
Large Language Models (LLMs) have revolutionized how machines handle complex tasks, including solving mathematical problems, writing code, and making sense of everyday situations. Enhancing the reasoning capabilities of these models remains a crucial challenge. While increasing model size has been a common approach, it often leads to diminishing returns and higher computational costs. A growing necessity exists to explore more effective and efficient strategies that improve reasoning without merely scaling up the models. It shifts the focus towards deeply understanding and refining the patterns that these models employ to execute reasoning tasks. Understanding these patterns can help optimize the utilization of resources, enabling the models to tackle more intricate problems effectively.
1.1. Understanding the Essence of Reasoning in AI
Reasoning in artificial intelligence refers to the ability of AI systems to process information, draw inferences, and make decisions in a manner that mimics human cognitive processes. Effective reasoning involves understanding context, identifying relevant information, and applying logical rules or strategies to solve problems. The core of AI reasoning lies in the model’s capacity to understand, interpret, and solve problems through inference and analysis.
1.2. Why Study Reasoning Patterns?
The focus on studying reasoning patterns is crucial because it allows for the optimization of computational resource utilization. Rather than blindly scaling up models, understanding how models reason enables the development of more efficient algorithms and architectures. Optimizing these reasoning patterns can lead to improved model performance, reducing computational costs, and enhancing the ability to handle complex tasks. Analyzing reasoning patterns can reveal how models adapt to different problems, providing insights into their strengths and limitations across various tasks.
1.3. OpenAI’s O1 Model: A New Paradigm
The O1 model developed by OpenAI represents a significant advancement in LLMs, demonstrating unique approaches to reasoning across diverse domains. Unlike traditional models that rely heavily on parameter scaling, O1 emphasizes the optimization of reasoning patterns. This model employs a variety of strategies, including Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC), to tackle different problems.
2. Comparative Analysis of Reasoning Techniques
Several techniques have been developed to evaluate and compare the reasoning patterns of LLMs. These techniques, including Best-of-N (BoN), Step-wise BoN, Self-Refine, and Agent Workflow, enable models to process multiple responses or break down complex problems into more manageable components. While these methods enhance reasoning capabilities, their effectiveness varies significantly across different tasks such as mathematics and coding. By comparing these methods, we can better understand their strengths and limitations.
2.1. Test-Time Compute Methods
Test-time compute methods involve techniques applied during the evaluation or testing phase of a model, focusing on enhancing its reasoning and problem-solving abilities without altering the trained parameters.
2.1.1. Best-of-N (BoN)
BoN involves generating multiple responses for a given prompt and selecting the best one based on certain criteria, such as coherence or accuracy.
2.1.2. Step-wise BoN
Step-wise BoN extends the BoN approach by applying it iteratively at each step of a reasoning process, allowing for refinement and correction along the way.
2.1.3. Self-Refine
Self-Refine allows the model to refine its responses iteratively based on its self-critique, improving the quality and accuracy of the final output.
2.1.4. Agent Workflow
Agent Workflow involves designing a structured process where different AI agents or modules collaborate to solve a complex task, leveraging their specialized capabilities.
2.2. Traditional vs. O1 Model Approaches
Traditional methods often depend on scaling parameters, which increases computational costs without always guaranteeing improved reasoning. The O1 model diverges from this approach by optimizing specific reasoning patterns, making it more efficient and adaptable.
2.3. Strengths and Weaknesses Across Domains
The effectiveness of each method varies across different domains. For instance, Divide and Conquer and Method Reuse are particularly effective in math and coding tasks, while Context Identification and Emphasizing Constraints are better suited for commonsense reasoning.
3. Core Reasoning Patterns of the O1 Model
The O1 model uses six primary reasoning patterns: Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC). These patterns are observed to vary across different domains, indicating that the model adapts its strategies based on the nature of the problem.
3.1. Systematic Analysis (SA)
Systematic Analysis involves a structured, step-by-step approach to problem-solving, ensuring that all aspects of the problem are thoroughly examined and understood before a solution is attempted.
3.2. Method Reuse (MR)
Method Reuse refers to the model’s ability to apply previously learned solutions or strategies to new, similar problems, enhancing efficiency and reducing redundancy.
3.3. Divide and Conquer (DC)
Divide and Conquer involves breaking down complex problems into smaller, more manageable sub-problems, solving each individually, and then combining the solutions to solve the original problem.
3.4. Self-Refinement (SR)
Self-Refinement allows the model to iteratively improve its responses by critically evaluating its outputs and making necessary adjustments to enhance accuracy and coherence.
3.5. Context Identification (CI)
Context Identification involves recognizing and understanding the specific context in which a problem is presented, allowing the model to apply the most relevant information and strategies for solving it.
3.6. Emphasizing Constraints (EC)
Emphasizing Constraints focuses on identifying and prioritizing the constraints or limitations within a problem, ensuring that the proposed solutions adhere to these boundaries.
3.7. Domain-Specific Adaptations
The O1 model adapts its reasoning strategies based on the domain. For instance, Divide and Conquer and Method Reuse are used extensively in math and coding tasks, while Context Identification and Emphasizing Constraints are more prevalent in commonsense reasoning.
4. Mathematical Reasoning: The AIME Benchmark
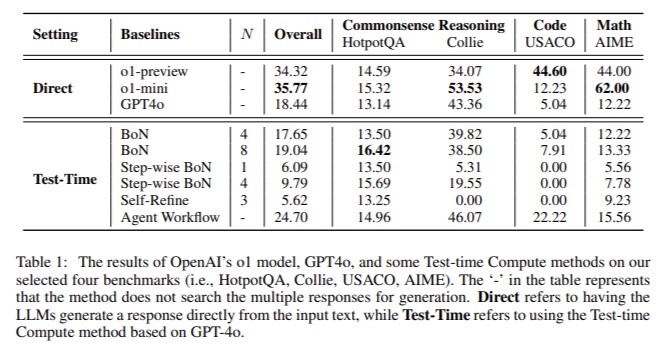
In mathematics, the O1 model was tested on the AIME benchmark, known for its complex problems that require deep, multi-step reasoning. The model showed significant improvements over traditional methods, achieving a 60% accuracy rate on the AIME24 dataset.
4.1. AIME Benchmark Overview
The AIME (American Invitational Mathematics Examination) is an examination used to identify students with exceptional mathematical problem-solving skills. It includes complex problems that require deep, multi-step reasoning.
4.2. O1 Model Performance
The O1 model achieved 60% accuracy on the AIME24 dataset, surpassing traditional methods. This performance highlights the model’s ability to handle complex mathematical problems through optimized reasoning patterns.
4.3. Role of Divide and Conquer
Divide and Conquer was crucial in the O1 model’s success in mathematical tasks. By breaking down problems into smaller components, the model could solve each part before combining the solutions to arrive at a final answer.
4.4. Comparison with GPT-4o
Unlike models like GPT-4o, which rely more heavily on parameter scaling, the O1 model’s structured approach to problem-solving allowed it to excel in multi-step reasoning tasks, where parameter scaling alone is insufficient.
5. Coding Tasks: Evaluating with USACO Dataset
For coding tasks, the O1 model was evaluated using the USACO dataset, a benchmark that assesses algorithmic and problem-solving skills. The model outperformed traditional Test-time computing methods like Step-wise BoN and Self-Refine.
5.1. USACO Dataset Overview
The USACO (USA Computing Olympiad) dataset tests a model’s algorithmic and problem-solving skills, presenting coding challenges of varying difficulty levels.
5.2. Performance Analysis
The O1 model’s performance on the USACO dataset exceeded that of traditional Test-time computing methods like Step-wise BoN and Self-Refine, demonstrating its superior coding capabilities.
5.3. Method Reuse and Self-Refinement
Method Reuse, where the model applied known solutions to similar problems, and Self-Refinement, which ensured accurate solutions through iterative adjustments, were vital in the model’s success.
5.4. Handling Complex Constraints
The model’s ability to manage complex constraints and ensure precise solutions through Self-Refinement was crucial in these tasks, highlighting its robustness and adaptability.
6. Commonsense Reasoning: HotpotQA Dataset
In the HotpotQA dataset, which tests commonsense reasoning, the O1 model surpassed existing methods, achieving an accuracy of 35.77%, higher than BoN’s 34.32%. The O1 model’s capacity to process multiple reasoning paths concurrently and identify context-specific constraints was critical in its success.
6.1. HotpotQA Dataset Overview
The HotpotQA dataset is designed to evaluate a model’s ability to perform commonsense reasoning by answering complex, multi-hop questions that require integrating information from multiple sources.
6.2. Comparative Results
The O1 model achieved an accuracy of 35.77% on the HotpotQA dataset, outperforming BoN’s 34.32%. This improvement underscores the model’s enhanced commonsense reasoning capabilities.
6.3. The Importance of Context Identification
Context Identification was particularly important in commonsense reasoning tasks. The model’s ability to recognize and utilize relevant contextual information allowed it to outperform others in this area.
6.4. Flexibility in Reasoning Strategies
Unlike mathematical or coding tasks, where the model relied on structured problem-solving, commonsense reasoning required more flexibility. The O1 model’s varied reasoning strategies allowed it to excel in this domain.
7. Key Takeaways and Comparative Insights
The study’s results highlight the significance of understanding the reasoning patterns used by LLMs. Traditional methods like BoN and Step-wise BoN were effective in certain contexts but fell short in tasks requiring multi-step reasoning or domain-specific prompts. The O1 model, in contrast, demonstrated an ability to adapt its reasoning patterns depending on the task, making it more versatile and effective in handling a broader range of problems.
7.1. Summary of Findings
The O1 model demonstrated six key reasoning patterns: Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC). The Divide and Conquer approach led to a 60% accuracy rate on the AIME24 mathematics benchmark, significantly outperforming other methods. In coding tasks using the USACO dataset, the O1 model excelled by leveraging Method Reuse and Self-Refinement, achieving higher accuracy than traditional methods. The O1 model outperformed other models in the HotpotQA commonsense reasoning task, with a 35.77% accuracy, compared to 34.32% for BoN. The adaptability of the O1 model’s reasoning patterns allowed it to succeed across different domains, making it more effective than models relying solely on parameter scaling.
7.2. Adaptability as a Key Advantage
The adaptability of the O1 model is a critical advantage. Its ability to adjust reasoning patterns based on the task at hand makes it more effective across various domains compared to models that rely solely on parameter scaling.
7.3. Implications for Future AI Development
These findings have significant implications for the future development of AI. By focusing on optimizing reasoning patterns, developers can create more efficient and versatile models that can handle a wider range of complex tasks.
8. COMPARE.EDU.VN: Your Guide to Informed Decisions
Understanding the nuances of AI model performance can be challenging, especially when comparing different approaches and technologies. COMPARE.EDU.VN offers comprehensive and objective comparisons, helping you make informed decisions about the best solutions for your needs.
8.1. Why Choose COMPARE.EDU.VN?
COMPARE.EDU.VN provides detailed comparisons of various products, services, and ideas, including AI models. Our platform offers clear and unbiased assessments, empowering you to choose the best options.
8.2. Features and Benefits
- Comprehensive Comparisons: Detailed analyses of different options.
- Objective Assessments: Unbiased evaluations of strengths and weaknesses.
- User Reviews: Insights from users and experts.
- Side-by-Side Analysis: Easy-to-understand comparisons of features and specifications.
- Customized Recommendations: Tailored advice based on your specific needs and requirements.
8.3. How COMPARE.EDU.VN Simplifies Decision-Making
COMPARE.EDU.VN simplifies decision-making by providing all the information you need in one place. Our easy-to-navigate platform allows you to quickly compare different options and find the perfect solution for your specific needs. Whether you’re comparing AI models or choosing the best educational resources, COMPARE.EDU.VN helps you make confident and informed decisions.
9. Conclusion: The Future of AI Reasoning
The study of OpenAI’s O1 model reveals the importance of optimizing reasoning patterns in LLMs. By adapting its strategies to different domains, the O1 model demonstrates superior performance compared to traditional methods that rely solely on parameter scaling. This approach paves the way for developing more efficient, versatile, and effective AI systems. COMPARE.EDU.VN is committed to providing you with the latest insights and comparisons, ensuring you stay informed about the advancements in AI and make the best decisions for your future.
9.1. Final Thoughts on O1 Model’s Impact
The O1 model’s innovative approach to reasoning marks a significant step forward in AI development. Its ability to adapt to different tasks and optimize reasoning patterns sets a new standard for future AI models.
9.2. The Ongoing Evolution of AI
AI is continuously evolving, with new models and techniques emerging regularly. Staying informed about these advancements is crucial for making the most of AI’s potential.
9.3. Make Informed Decisions with COMPARE.EDU.VN
Don’t let the complexity of AI overwhelm you. Visit COMPARE.EDU.VN today to explore detailed comparisons and make informed decisions.
10. Frequently Asked Questions (FAQ)
1. What are Large Language Models (LLMs)?
Large Language Models are AI models trained on vast amounts of text data to understand and generate human-like text.
2. What is the primary challenge in improving LLMs?
The primary challenge is enhancing their reasoning capabilities without solely relying on scaling up model parameters.
3. What is the O1 model?
The O1 model is an LLM developed by OpenAI that emphasizes optimizing reasoning patterns rather than parameter scaling.
4. What are the six key reasoning patterns used by the O1 model?
The six key reasoning patterns are Systematic Analysis (SA), Method Reuse (MR), Divide and Conquer (DC), Self-Refinement (SR), Context Identification (CI), and Emphasizing Constraints (EC).
5. How does the O1 model perform in mathematical reasoning tasks?
The O1 model achieved 60% accuracy on the AIME24 dataset, demonstrating significant improvements over traditional methods.
6. What is the USACO dataset used for?
The USACO dataset is used to evaluate a model’s algorithmic and problem-solving skills in coding tasks.
7. How did the O1 model perform on the HotpotQA dataset?
The O1 model achieved an accuracy of 35.77% on the HotpotQA dataset, outperforming other methods in commonsense reasoning.
8. What is Method Reuse (MR)?
Method Reuse refers to the model’s ability to apply previously learned solutions or strategies to new, similar problems.
9. How does Divide and Conquer (DC) help in problem-solving?
Divide and Conquer involves breaking down complex problems into smaller, more manageable sub-problems, solving each individually, and then combining the solutions.
10. Where can I find comprehensive comparisons of AI models and other products?
You can find detailed and objective comparisons on COMPARE.EDU.VN, which helps you make informed decisions.
If you’re struggling to compare different AI models and are seeking detailed, objective evaluations, visit COMPARE.EDU.VN. We provide comprehensive comparisons to help you make informed decisions. Contact us at 333 Comparison Plaza, Choice City, CA 90210, United States, or via WhatsApp at +1 (626) 555-9090. Explore more at compare.edu.vn.