Can Your Unit Gpu Compare to the latest models for your specific needs? COMPARE.EDU.VN provides an in-depth comparison of GPU units, focusing on performance, features, and pricing, to help you make an informed decision. Discover the best GPU for your applications with our detailed analysis, covering everything from memory capacity to cost-effectiveness, and find the perfect balance between performance and budget.
1. Understanding Colab’s GPU Offerings
Google Colaboratory (Colab) has evolved from a completely free service offering high-end GPUs to a platform where users pay for GPU time. Initially, Colab provided invaluable resources to the research community. However, the rise of AI art generation tools built on Colab has expanded its user base, leading to adjustments in its pricing model. While the Tesla T4 remains free, Colab now charges rates that align more closely with market standards for GPU access. Students, hobbyists, and researchers with limited budgets can still benefit from the free T4 GPU. For those willing to pay, Colab’s simplicity and payment structure make it a convenient choice for various GPU-intensive tasks.
2. Decoding Colab’s Pricing Structure
Understanding the costs associated with Colab’s GPUs requires a bit of investigation, as the hourly rates aren’t explicitly stated. This section clarifies how Colab’s pricing works, helping you estimate the expenses for different GPU options.
2.1. Compute Units
Colab uses “compute units” to charge for GPU time. Each unit costs $0.10, and you can purchase them in blocks of 100 for $10. There are no bulk discounts available. To sign up for Colab and view pricing plans, visit here. You can opt for a pay-as-you-go approach or subscribe to Colab Pro or Pro+ for additional features.
2.2. Monitoring Your Units
You can monitor your remaining units and the current session’s cost by clicking the dropdown arrow in the upper right corner of Colab and selecting “View resources”.
The sidebar that appears displays your balance and usage. This sidebar is also a convenient tool for monitoring GPU memory usage during code execution.
3. Estimating GPU Costs
GPU pricing on Colab may fluctuate based on demand and location. Here are some estimates based on data collected on April 10th and April 22nd, 2024, in Southern California.
| GPU | Units/hr | $/hr | Time (h:m) | Date Checked |
|---|---|---|---|---|
| T4 | 1.84 | $0.18 | 54:20 | 2024-04-10 |
| V100 | 4.91 | $0.49 | 20:21 | 2024-04-10 |
| L4 | 4.82 | $0.48 | 20:47 | 2024-04-22 |
| A100 | 11.77 | $1.18 | 8:30 | 2024-04-22 |
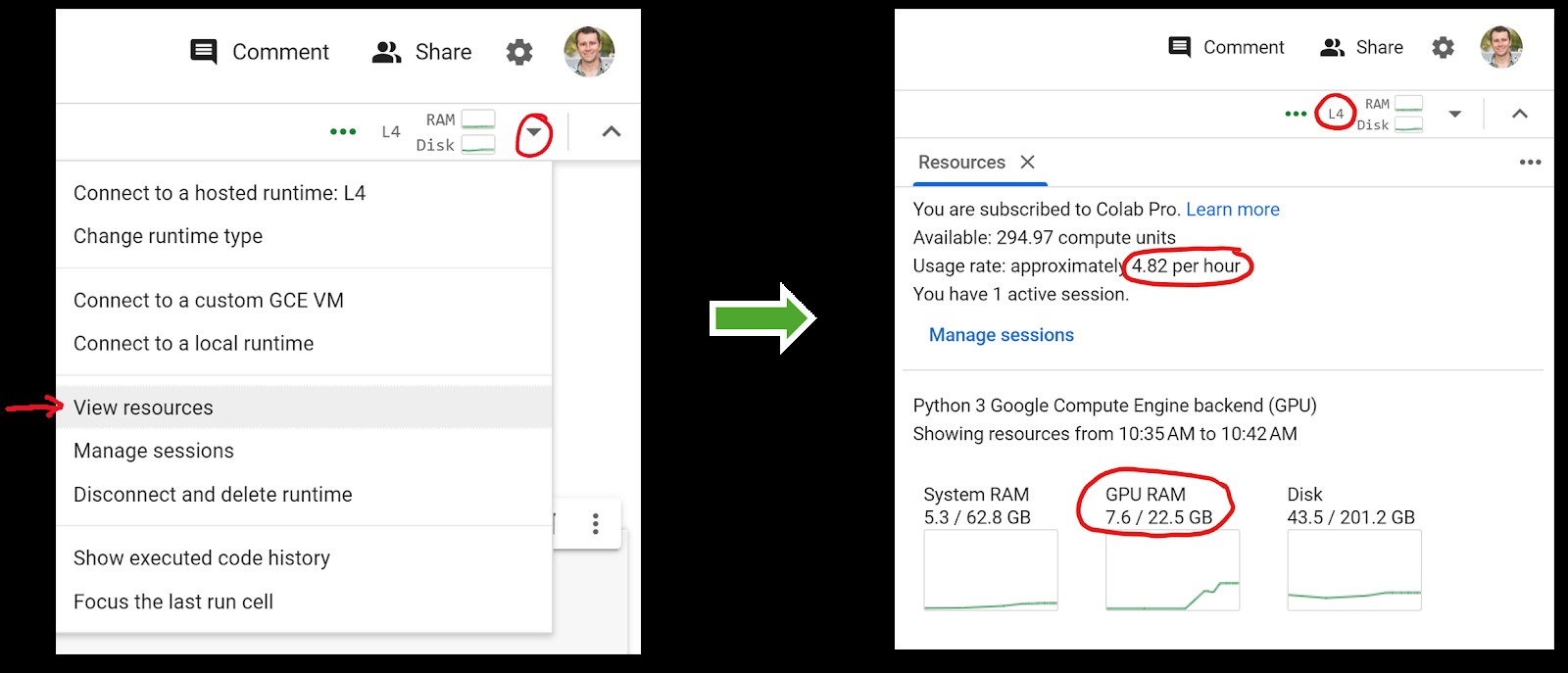
These numbers provide a general idea of the costs involved. Usage rates may vary depending on your account type and location. For example, a free account using the T4 GPU may have limited runtime.
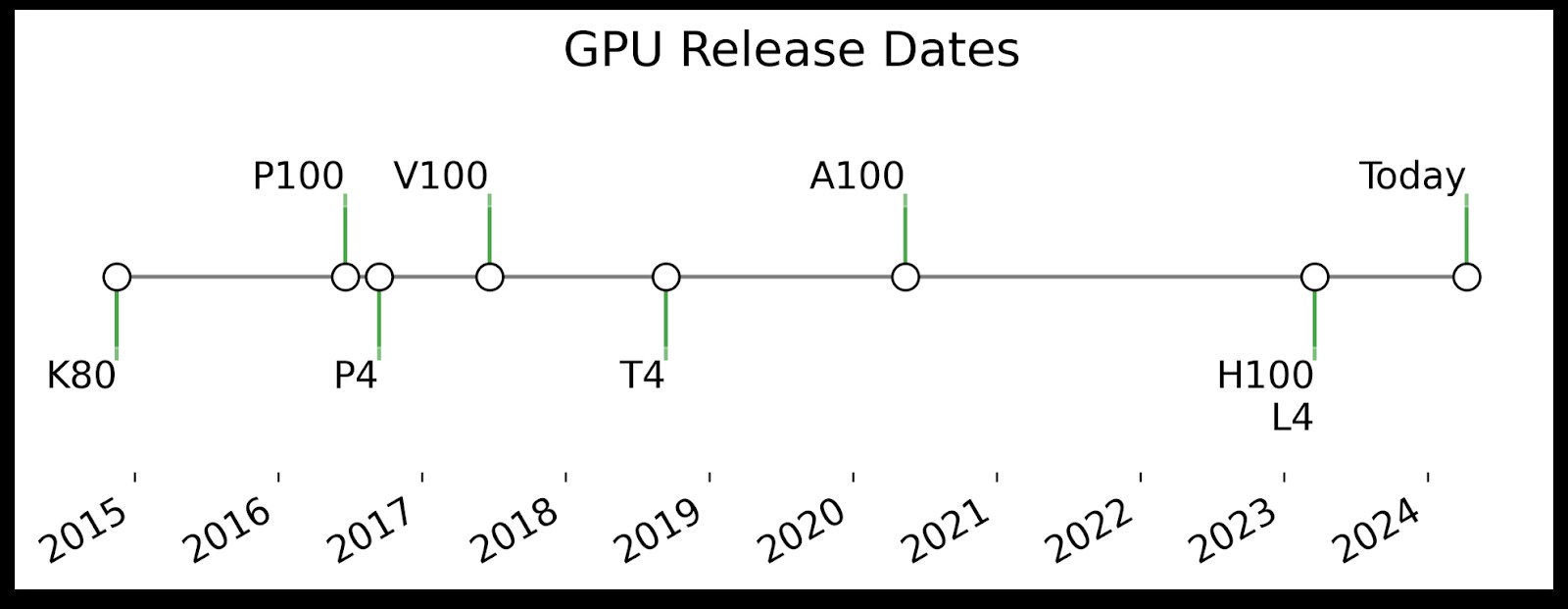
4. A Look at GPU Timeline
The evolution of GPUs available on Colab is marked by significant advancements in architecture and capabilities. Understanding this timeline helps in appreciating the performance differences between various models.
4.1. Key GPU Models on Colab
The following table highlights the key specifications of the GPUs currently available on Colab:
| GPU Model | Architecture | Launch Date | VRAM | Website |
|---|---|---|---|---|
| V100 | Volta | 6/21/17 | 16 GB | Details |
| T4 | Turing | 9/13/18 | 15 GB | Details |
| A100 | Ampere | 5/14/20 | 40 GB | Details |
| L4 | Ada Lovelace | 3/21/23 | 22.5 GB | Details |
Notes:
- The A100 is also available in an 80GB version, though not directly through Colab.
- The T4 has 16GB of VRAM, but only 15GB is usable due to error code correction (ECC). ECC protects against bit flips caused by cosmic rays.
4.2. Future GPU Models
While not yet available on Colab, the following GPUs represent the cutting edge of GPU technology:
| GPU Model | Architecture | Launch Date | VRAM | Website |
|---|---|---|---|---|
| H100 | Hopper | 3/21/23 | 80GB | Details |
| B100 | Blackwell | Coming 2024 | ? | .. |
5. Assessing Performance & Features
The performance of a GPU depends heavily on the specific use case. This section provides a comparison of the GPUs available on Colab based on various factors.
5.1. Speed Benchmarks
Here are some anecdotal benchmarks based on fine-tuning a Large Language Model (LLM) on a single GPU:
Reduced Settings
When reducing the sequence length to 512 and the batch size to 1, the time required for 500 training steps is approximately:
- T4 = 12 min
- L4 = 5.5 min (2.2x faster than T4)
- A100 = 2 min (6x faster than T4)
Desired Settings
When using a sequence length of 1,024 and an effective training batch size of 4, the performance difference becomes more pronounced:
| GPU | Seq Len | Grad Check | Batch Size | Accumulation Steps | Memory Use | Time | Speed vs. T4 |
|---|---|---|---|---|---|---|---|
| T4 | 1024 | True | 1 | 4 | 7.0GB | ~2h 10min | 1x |
| L4 | 1024 | False | 1 | 4 | 17.5GB | ~47min | 2.8x |
| A100 | 1024 | False | 2 | 2 | 28.1 GB | ~10min | 13x |
Memory is a crucial factor, as demonstrated by these results.
5.2. TeraFLOPS Comparison
TeraFLOPS (TFLOPS) provide a general indication of GPU performance. Here’s a comparison of the GPUs available on Colab:
| GPU | teraFLOPS | Precision | Mult. |
|---|---|---|---|
| T4 | 65 | FP16 | – |
| L4 | 121 | FP16 | 1.9x |
| A100 | 312 | FP16 | 4.8x |
These numbers align reasonably well with the observed speed gains in practical applications.
5.3. Cost-Effectiveness
The T4 may be the most cost-effective option for tasks that fit within its memory constraints. However, the A100 can be cheaper when additional memory is required. Engineering time savings and faster iteration are significant benefits of using higher-performance GPUs.
6. FlashAttention on the T4
FlashAttention is a technique that improves the speed and memory usage of attention calculations, particularly at longer sequence lengths. It is implemented in PyTorch v2.2 as “Squared Dot Product Attention” (sdpa). While the original FlashAttention v2 isn’t implemented for the T4, SDPA is supported and provides similar benefits. In HuggingFace, you can select the attention implementation using the attn_implementation parameter in the from_pretrained function.
7. bfloat16 Support
bfloat16 is a data type that offers advantages over float16 for neural network training. It is supported by newer GPUs like the A100 and L4, but not by older GPUs like the V100 and T4. bfloat16 has a wider range than float16, making it less prone to numerical instability issues like fluctuating loss functions and erratic performance metrics. Switching between float16 and bfloat16 depending on the GPU can be cumbersome, as it requires modifying code with GPU-specific checks.
8. Making the Right Choice
Develop and test code on the T4 to save money. For full training runs, consider using an A100 to leverage its higher performance.
9. COMPARE.EDU.VN: Your Partner in Making Informed Decisions
Choosing the right GPU for your needs involves considering various factors such as performance, memory capacity, cost-effectiveness, and specific features like FlashAttention and bfloat16 support. At COMPARE.EDU.VN, we understand the challenges in comparing different options objectively. That’s why we provide detailed and unbiased comparisons of GPUs, listing the advantages and disadvantages of each option. Our comprehensive analyses help you compare features, specifications, prices, and other crucial factors. We also offer reviews and feedback from users and experts, so you can make the best choice for your needs and budget.
10. Ready to Decide?
Don’t let the complexity of GPU comparisons hold you back. Visit COMPARE.EDU.VN today to explore our detailed comparisons and make a smart decision. Your perfect GPU is just a click away!
Address: 333 Comparison Plaza, Choice City, CA 90210, United States.
Whatsapp: +1 (626) 555-9090.
Website: COMPARE.EDU.VN
FAQ: Frequently Asked Questions about Colab GPUs
1. What is Google Colab, and how does it relate to GPUs?
Google Colab is a cloud-based platform that allows users to write and execute Python code, including machine learning tasks, in a browser. It provides access to free GPUs, such as the Tesla T4, and paid options like the V100, L4, and A100, making it a popular choice for researchers, students, and developers.
2. How can your unit GPU compare to other available options in Colab?
Your unit GPU can compare to other options based on factors like processing speed, memory capacity (VRAM), architecture, and support for features like bfloat16 and FlashAttention. COMPARE.EDU.VN provides detailed comparisons to help you assess these factors.
3. What factors should I consider when comparing GPU units in Colab?
When comparing GPU units, consider your specific workload, memory requirements, processing speed, and budget. The A100, for example, offers the highest performance but is also the most expensive, while the T4 is free but has limited memory and speed.
4. Can your unit GPU handle large datasets and complex models?
Whether your GPU can handle large datasets and complex models depends on its memory capacity (VRAM). GPUs like the A100 with 40GB of VRAM are better suited for large datasets and complex models than the T4 with 15GB.
5. What are the key differences between the Tesla T4, V100, L4, and A100 GPUs in Colab?
The Tesla T4 is a free, entry-level GPU, while the V100, L4, and A100 are paid options offering progressively higher performance and memory. The A100 is the most powerful, followed by the L4 and V100. The T4 is suitable for basic tasks and learning, while the others are better for more demanding workloads.
6. How does the cost of using different GPUs in Colab compare?
The cost varies based on the GPU model and usage time. The T4 is free, while the V100, L4, and A100 are charged based on compute units per hour. The A100 is the most expensive, followed by the L4 and V100. Check the current pricing on Colab’s website or COMPARE.EDU.VN for the latest information.
7. What is FlashAttention, and how does it affect GPU performance in Colab?
FlashAttention is a technique that optimizes attention calculations in neural networks, improving speed and memory usage. It’s particularly beneficial for longer sequence lengths. While the original FlashAttention v2 isn’t available on the T4, SDPA (Squared Dot Product Attention) provides similar benefits.
8. What is bfloat16, and why is it important for GPU performance in Colab?
bfloat16 is a data type that offers advantages over float16 for neural network training, providing a wider range and better numerical stability. It’s supported by newer GPUs like the A100 and L4 but not the V100 and T4.
9. How can COMPARE.EDU.VN help me choose the right GPU for my needs?
COMPARE.EDU.VN provides detailed comparisons of GPU units, including performance benchmarks, cost analysis, and feature comparisons. We also offer user reviews and expert opinions to help you make an informed decision based on your specific requirements and budget.
10. Where can I find the most up-to-date information on Colab GPU pricing and availability?
You can find the most up-to-date information on Colab GPU pricing and availability on Colab’s website or by visiting compare.edu.vn, where we regularly update our comparisons with the latest data.